第三章:栈和队列(数据结构)
\(\color{blue}{\textbf{栈:线性结构}}\begin{cases}\color{red} {顺序\to操作,} \\ \color{red}{链式\to操作. }\\ \end{cases}\)
运算受限的叫栈
后进先出,先进后出

栈的操作
①进出栈顺序
②求栈的容量
\(③栈中元素\begin{equation}\begin{cases} 入栈, \\ 出栈. \\ \end{cases}\end{equation}\)
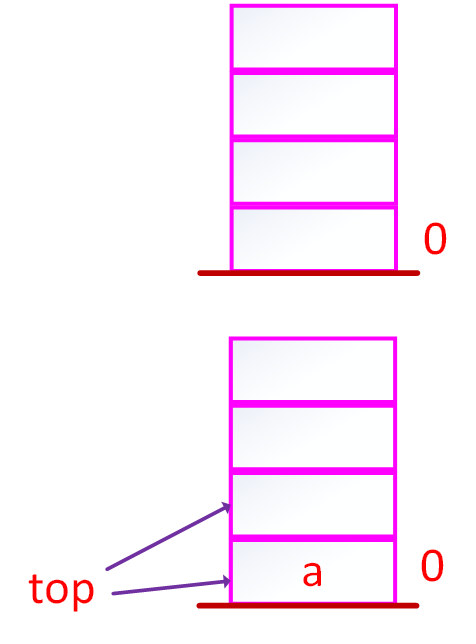

如果空栈为零的,top 先进来然后再做++
,如果是-1先加加在进
若果满足top=栈容量-1 n-1
入栈:先进元素再移动top
出栈:先动top,然后读取元素
④
求实际元素个数

|top-bottom|=3-0=3
bottom 不会动
top 移动,随top移动改变
|
新东方赵海英习题 2. 递归过程或函数调用时,处理参数及返回地址,要用一种称为( )的数据结构。 |
| A.队列 |
| B.多维数组 |
| C.栈 |
| D. 线性表 |
| C |
|
C [分析] 本题考查数据结构基础知识。 在函数调用过程中形成嵌套时,则应使最后被调用的函数最先返回,递归函数执行时也是如此。例如,用递归方式求4的阶乘(以factorial(n)表示求n的阶乘)的过程如下所示: factorial(4)=4*factorial(3) =4*(3*factorial(2)) =4*(3*(2*factorial(1))) =4*(3*(2*1) =4*(3*2) =4*6 =24 显然,要求4的阶乘,需要通过递归调用求出3的阶乘,要求出3的阶乘,必须先求出2的阶乘,依此类推,求出1的阶乘后才能得到2的阶乘,然后才能得到3和4的阶乘。该求解过程中的函数调用和返回需要满足后调用先返回的特点,因此需要使用栈结构。 |
限定只在表的一端( ( 表尾) ) 进行插入和删除操作的线性表
- 特点: 后进先出( ( LIFO) )
- 允许插入和删除
允许插入和删除的一端称为 栈顶( top ) ,另一端称为 栈底( bottom)

1)顺序栈——栈的顺序存储结构
2)链栈——栈的链式存储结构
| 若已知一个栈的入栈顺序是1,2,3,...,n,其输出序列为P1,P2,P3,...,Pn,若P1是n,则Pi是 |
| A.i |
| B.n-i |
| C.n-i+1 |
| D.不确定 |
| C |
|
C、n-i+1。 栈的排列遵循先进后(即后进先出)出的原则,因为P1是n,是出栈的第一个数字。说明在之前进栈的数字都没有出栈,所以这个顺序是确定的,还可以知道,最后出栈的一定是数字1,也就是Pn,代入这个式子。 栈作为一种数据结构,是一种只能在一端进行插入和删除操作的特殊线性表。它按照先进后出的原则存储数据,先进入的数据被压入栈底,最后的数据在栈顶,需要读数据的时候从栈顶开始弹出数据。栈具有记忆作用,对栈的插入与删除操作中,不需要改变栈底指针。
扩展资料: 进栈(PUSH)算法 ①若TOP≥n时,则给出溢出信息,作出错处理(进栈前首先检查栈是否已满,满则溢出;不满则作②); ②置TOP=TOP+1(栈指针加1,指向进栈地址); ③S(TOP)=X,结束(X为新进栈的元素); 退栈(POP)算法 ①若TOP≤0,则给出下溢信息,作出错处理(退栈前先检查是否已为空栈, 空则下溢;不空则作②); ②X=S(TOP),(退栈后的元素赋给X): ③TOP=TOP-1,结束(栈指针减1,指向栈顶)。 |
限定在表尾进行插入和删除操作的顺序表
类型定义:
typedef struct {
SElemType *base;
SElemType *top;
int stacksize;
} SqStack;
SqStack s
|
74.计算机组成原理王道最后8套题第四套第一,2题025页 2.若一个栈以向量V[1..n]存储,初始栈顶指针top为n+1,则x进栈的正确操作是( )。 |
| A. top=top+1; V[top]=x |
| B. V[top]=x; top=top+1 |
| C. top=top-1; V[top]=x |
| D. V[top]=x; top=top-1 |
| C |
|
2. C。 [解析]考查栈的操作。初始时栈顶指针top=n+1,所以该栈应该是从高地址向低地址生长。且n+1不在向量的地址范围,因此应该先将top减1,再存储。即选C。 注意:对于顺序存储的栈(对于队列也类似),如果存储的定义不同,则出入栈的操作也不相同(并不是固定的),这要看栈项指针指向的是栈顶元素,还是栈顶元素的下一位置。 |
说明:
- base称为栈底指针,始终指向栈底;
当base = NULL时,表明栈结构不存在。
- top为栈顶指针
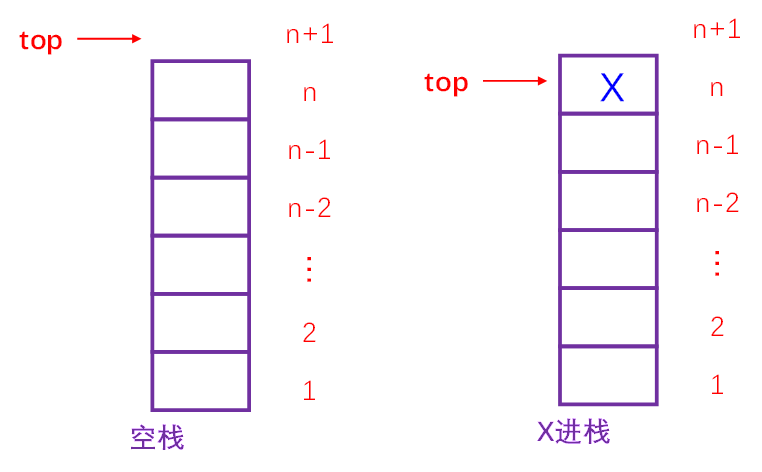
a. top的初始值指向栈底,即top=base
a. top的初始值指向栈底,即top=base
b. 空栈:当top=base时为栈空的标记
c. 当栈非空时,top的位置:指向当前栈
顶元素的下一个位置
- stacksize ——当前栈可使用的最大容量
//判断栈空
bool StackEmpty(SqStack S) {
if (S.top == -1)
return true;
else
return false;
}
//进栈
bool Push(SqStack& S,ElemType x) {
if (S.top == MaxSize - 1)/ /判断栈是否满了
return false;
s.data[++S.top] = X; //先自加1, 再进栈操作
return true;
}
//出栈
bool Pop(SqStack& S, ElemType& x) {
if (S.top == -1) //判断栈是否为空,不为空一直执行
return false; //如果空栈返回false
X = s.data[S.top--]; //先赋值,再减一
return true;
}
//读出栈顶元素
bool GetTop(SqStack S,ElemType& x) {
if (s.top == -1)
return false;
X = S.data[S.top];
return true;
}
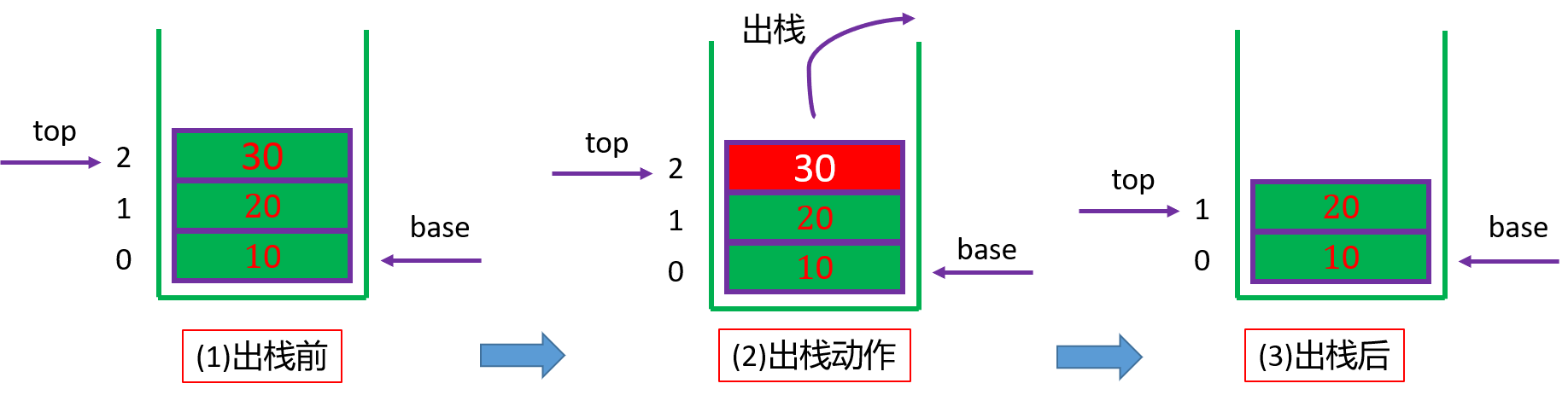
进栈示例

入栈:先进元素再移动top
退栈示例
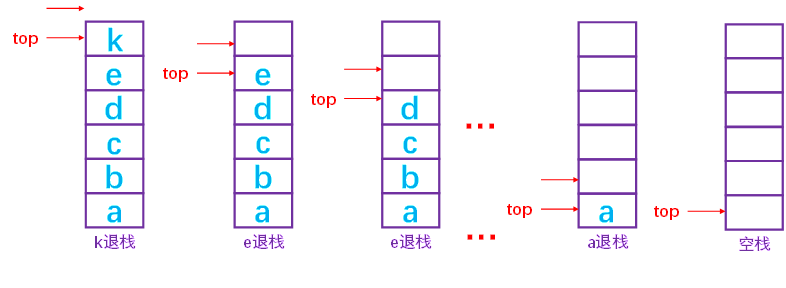
出栈:先动top,然后读取元素
|
74.数据结构王道最后8套题第一套第一,1题001页 1.已知一个栈的进栈序列是1、2、3、... n,其输出序列为p1,p2,…,pn,若p1=3,则p2为( )。 |
| A.2或4、5、...n都有可能 |
| B.可能是1期 |
| C.一定是 2 |
| D.只可能是2或4 |
| A |
| 1. A。 (解析考查出入栈操作的性质。当p1=3, 表示3最先出栈,前面1、2应在栈中,此时若出栈操作,则p2 应为2;此时若进栈操作(进栈1次或多次),则p2 为4、5、 ... n都有可能,故选A。 |
top-- 元素退栈
最后一个空栈
几点说明:
栈空条件:s.top=s.base此时不能出栈
栈满条件:s.top-s.base>=s.stacksize
进栈操作:*stop++=e;或*s.top=e;s.top++;
退栈操作:e=*--s.top;或s.top--;e=*s.top;
当栈满时再做进栈运算必定产生空间溢出,简称“上溢”
当栈空时再做退栈运算也将产生溢出,简称:称“下溢”
栈基本操作的实现
Status InitStack(SqStack &S) //栈的初始化操作
Status GetTop(SqStack S, SElemType &e) // 取栈顶元素
Status Push(SqStack &S, SElemType e)//进栈操作
Status Pop(SqStack &S, SElemType &e) //退栈操作
 |
|
 |
|
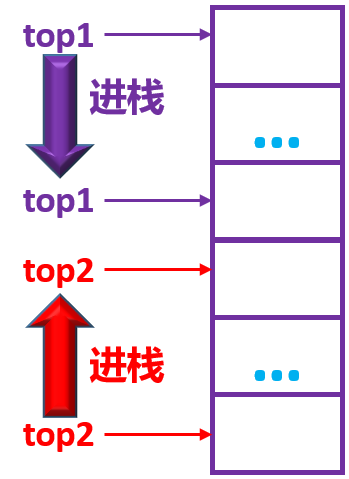
两个顺序栈共享数组S【0…n-1】,其中第一个栈的栈顶指针top1的初始值为-1,第二个栈的栈顶指针top2的初始值为n,则判断该共享栈满的条件是( )
top1+1=top2
这道题要理解 “第一个栈的栈顶指针top1的初始值为-1,第二个栈的栈顶指针top2的初始值为n“,这句话表明一个栈从头开始,另一个栈则是从尾开始,随着两栈的增加,栈顶指针不断的接近,当top1+1= top2时就代表满了
- 不带头结点的单链表,其插入和删除操作仅限制在表头位置上进行。
链表的头指针即栈顶指针。
- 类型定义:
typedef struct SNode{
SElemType data;
struct SNode *next;
}SNode, *LinkStack;
LinkStack s;
- 链栈示意图

- 栈空条件:s=NULL
- 栈满条件:无 / 无Free Memory可申请
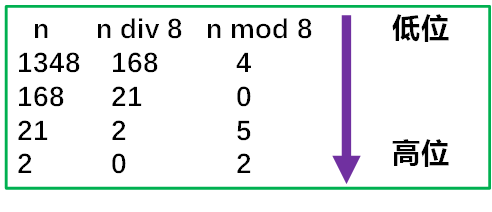
(1). 数制转换
十进制N和其它进制数的转换是计算机实现计
的基本问题,基于下列原理:
N=(n div d)*d+n mod d
( 其中:div为整除运算,mod为求余运算)
( 其中:div为整除运算,mod为求余运算)
例如 (1348) 10 =(2504) 8 ,其运算过程如下:
(2).表达式求值
- 算符间的优先级关系 p52~p53
先括弧内后括弧外
- 左括号:比括号内的算符的优先级低
比括号外的算符的优先级高
比括号外的算符的优先级高
- 右括号:比括号内的算符的优先级低
比括号外的算符的优先级高
- #:优先级总是最低
- 为实现算符优先算法,可使用两个工作栈:
OPND栈:存数据或运算结果
OPTR栈:存运算符
算法思想:
1.初态: 置OPND栈为空;将“#”作为OPTR栈的栈底元素
2.依次读入表达式中的每个字符
1)若是操作数,则进入OPND栈;
2)若是运算符,则与OPTR栈的栈顶运算符进行优先权(级)的比较:
- 若读入运算符的优先权高,则进入OPTR栈;
- 若读入运算符的优先权高,则进入OPTR栈;
- 若读入运算符的优先权低,则OPTR退栈(退出原有的栈顶元素),
OPND栈退出两个元素(先退出b,再退出a),中间结果再进入OPND
栈;
- 若读入“)”,OPTR栈的原有栈的栈顶元素若为“(”,则OPTR退
出“(”;
- 若读入“#”,OPTR栈栈顶元素也为“#”,则OPTR栈退出“#”,结束。
- 例:3*(7-2)
例 2 、括号匹配的检验
假设在表达式中
等为正确的格式,
均为不正确的格式。
则检验括号是否匹配的方法可用
" 期待的急迫程度 " 这个概念来描述。
例如:考虑下列括号序列:
1 2 34 5 6 7 8
分析可能出现得不匹配得情况.
1 、到来的右括弧非是所 " 期待 " 的;
2 、到来的是“不速之客 "
3 、直到结束,也没有到来所 " 期待 " 的括弧,
算法的设计思想:
1 )凡出现左括弧,则进栈,
2 )凡出现右括弧,首先检查栈是否空
若栈空,则表明该 " 右括弧 " 多余
否则和栈顶元素比较,
若相匹配,则 " 左括弧出栈 "
否则表明不匹配
3 )表达式检验结束时,
若栈空,则表明表达式中匹配正确
否则表明 " 左括弧 " 有余
例 4 ,表达式求值
限于二元运算符的表达式定义:
表达式一(操作数) + (运算符) + (操作数)
操作数::=简单变量|表达式
简单变量::=标识符|无符号整数
表达式的三种标识方法:
设 Exp=S1 + OP + S2
则称 OP + S1 +S2 为前缀表示法
S1+ OP +S2 为中缀表示法
S1+S2+OP 为后缀表示法
例如: Exp=a x b+(c-d/e)x f
前缀式: + x ab x-c/def
中缀式: a x b+c-d/exf
后缀式:ab x Cde/-fx+
结论:1)操作数之间的相对次序不变;
2)运算符的相对次序不同.
3)中缀式丢失了括弧的信息,致使运算的次序不确定.
4)前缀式的运算规则为:连续出现的两个操作数和他们之间且仅靠他们的运算符构成一个最小表达式.
5 )后缀式的运算规则为:运算符在式中出现的顺序恰为表达式的运算顺序;每个运算符和在它之前出现且紧靠它的两个操作数构成一个最小表达式;
遇见数压栈,,遇见符号从栈里面出两个数
·如何从原表达式求得后缀式?
分析 " 原表达式 " 和 " 后缀式 " 中的运算符:
原表达式: a + b × c 一 d / e × f
后缀式: a b c × + d e / f ×一
每个运算符的运算次序要由它之后的
一个运算符来定,在后缀式中,优先数高
的运算符领先于优先数低的运算符。
从原表达式求得后缀式的规律为:
1 )设立暂存运算符的栈;
2 )设表达式的结束符为 " # " ,
予设运算符栈的栈底为“ # ”
3 )若当前字符是操作数,
则直接发送给后缀式;
4 )若当前运算符的优先数高于栈顶运算符则进栈;
5 )否则,退出栈顶运算符发送给后缀式;
6 )“( " 对它之前后的运算符起隔离作用," ) " 可视为自相应左括弧开始的表达式的结束符。
当在一个函数的运行期间调用另一个函数时,
在运行该被调用函数之前,
需先完成三项任务:
①将所有的实在参数、返回地址等信息传递给被调用函数保存;
②为被调用函数的局部变量分配存储区;
③将控制转移到被调用函数的入口。
从被调用函数返回调用函数之前,应该完成下列三项任务:
①保存被调函数的计算结果;
②释放被调函数的数据区;
③到依照被调函数保存的返回地址将控制转移到调用函数。
多个函数嵌套调用的规则是:
后调用先返回!
此时的内存管理实行 " 栈式管理 "
例如:
void main( ) { void a( ) { void b( ) {
… … …
a(); b();
… …
}//main }//a }//b
递归函数调用的实现
"层次” 主函数 0层
第1次调用 1层
……
第i次调用 i层
“递归工作栈”
—递归程序运行期间使用的数据存储区
"在作记录” 实在参数,局部变量,返回地址
进行fact(4)调用的系统栈的变化状态
递归的优缺点
优点:结构清晰,程序易读
恢复状态信息。时间开销大。
缺点:每次调用要生成工作记录,保存状态信息,入栈;返回时要出栈,
递归→非递归
方法1:尾递归、单向递归→循环结构
方法2:自用栈模拟系统的运行时栈
借助栈改写递归
递归程序在执行时需要系统提供栈来实现
仿照递归算法执行过程中递归工作栈的状态变化可写出相应的非递归程序
改写后的非递归算法与原来的递归算法相比,结构不够清晰,可读性较差,有的还需要经过一系列优化
1.顺序栈:类似于线性表的顺序映象实现,指向表尾的指针可以作为栈顶指针。
//栈的顺序存储表示( 动态分配)
#define STACK_INIT_SIZE 100
typedef struct {
SElemType *base;
SElemType *top;
int stacksize;
} SqStack;
//注意,非空栈时top始终在栈顶元素的下一个位置.
ADT Queue{
数据对象:D={ai|ai∈ElemSet, i=1,2..n,n≥O
数据关系:R={<ai-1,ai>|ai-1,ai∈D,i=2..n)约定其中a端为队列头,a,端为队列尾。
基本操作:
InitQueue(&Q) 操作结果:构造空队列Q
DestroyQueue(&Q)条件:队列Q已存在;操作结果:队列Q被销毁
ClearQueue(&Q) 条件:队列Q已存在;操作结果:将Q清空
QueueLength(Q) 条件:队列Q已存在操作结果:返回Q的元素个数,即队长
GetHead(Q,&e) 条件:Q为非空队列操作结果:用e返回Q的队头元素
EnQueue(&Q,e) 条件:队列Q已存在 操作结果:插入元素e为Q的队尾元素
DeQueue(&Q,&e) 条件:Q为非空队列―操作结果:删除Q的队头元素,用e返回值
......还有将队列置空、遍历队列等操作......
}ADT Queue
3.2.2队列的顺序表示和实现
队列的物理存储可以用顺序存储结构,也可用链式存储结构。相应地,
队列的存储方式也分为两种,即顺序队列和链式队列。
队列的顺序表示——用一维数组base[MAXQSIZE]
#define MAXQSIZE 100//最大队列长度
Typedef struct {
QElemType *base;//初始化的动态分配存储空间
int front; //头指针
int rear; //尾指针
}
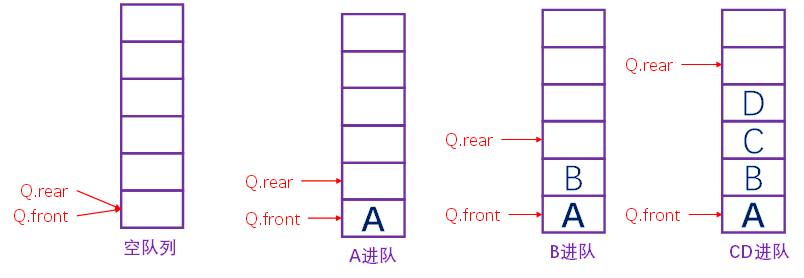
初始:front=rear=0 入队: base[rear]=x; rear++;

出队: x=base[front]; front++;
空队标志: front ==rear
进队时,将新元素按Q.rear指示位置加入,再将队尾指针增1,Q.rear ,Q.frear+1。
出队时,将下标为Qont的元素取出,再将队头指针增1,Q.front,Q.front+1。
队满时再进队将溢出出错:队空时再出队作队空处理。上图为“假满”
|
74.数据结构王道最后8套题第五套第一,2题033页 2.若以1234作为双端队列的输入序列,则既不能由输入受限的双端队列得到,也不能由输出受限的双端队列得到的输出序列是()。 |
| A.1234 |
| B.4132 |
| C.4231 |
| D.4213 |
| C |
| 2. C. [解析]考查双端队列的操作。输入受限的双端队列是两端都可以删除,只有一端可以插入的队列; 输出受限的双端队列是两端都可以插入,只有一端可以删除的队列。对于A, 可由输入受限的双端队列、也可由输出受限双端队列得到。对于BCD,因为4第一个出队,所以之前输入序列必须全部进入队列。对于B,在输入受限的双端队列中,输入序列是1234,全部进入队列后的序列也为1234, 两端都可以出,所以可以得到4132;在输出受限双端队列中,输入序列全部入队,1肯定和2挨着,所以得不到4132。对于C,在输入受限的双端队列中,输入序列是1234,全部进入队列后的序列也为1234,在4出队后不可以把2直接出队。在输出受限双端队列中,也是1和2在序列进入队列中后必须挨着。所以也得不到。对于D,在输入受限的双端队列中,输入序列是1234,全部进入队列后的序列也为1234,输出4后,应该是1和3,所以得不到;在输出受限双端队列中,输入序列1234,一-端进1,另一端进2,再一端进3,另一端进4.可得到4213的输出序列。因此选C。 |
|
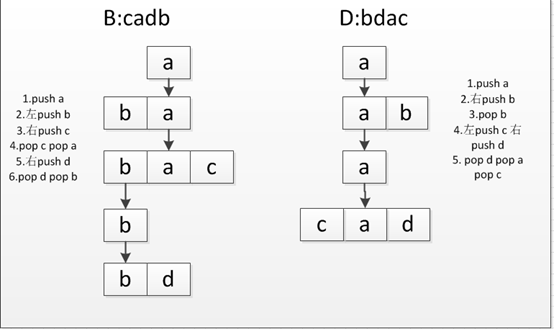
新东方赵海英习题 6. 已知输入序列为abcd 经过输出受限的双向队列后能得到的输出序列有() |
| A. dacb |
| B. cadb |
| C. dbca |
| D. bdac |
| BD |
|
输出受限的双端队列,即删除限制在一端进行,而插入仍允许在两端进行.先假设可在左右两端进队列,而只能在右端出队列,如图所示: 注意是出队受限的队列(单方向出队),入队可以两端入队,并且只限制进队的顺序,不限制是否全部进入才出队, |
| 多选 |
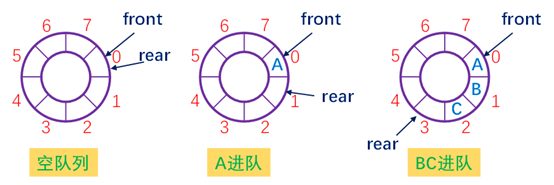
队列的顺序存储结构中用一组地址连续的存储单元依次存放从队头到队尾的元素。
附设两个指针 front 和 rear 分别指示队头元素的位置和队尾元素的下一个位置。
初始化建空队列时令 front = rear = 0 ,插入新的队尾元素时尾指针增 1 ,删除队头元素时头指针增 1
因为在对队列的操作中,头尾指针只增加不减小,导致被删除元素的空间永远无法重新利用。尽管队列中实际的元素个数可能远远小于存储空间的规模,但仍不能做入队列操作,该现象称为 " 假上溢 "
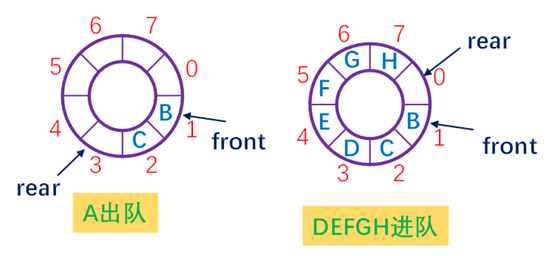
克服 " 假上溢“现象的方法是将顺序队列想象为一个首尾相接的圆环,称之为循环队列。
循环队列中无法通过 Q.front = Q. rear 来判断队列“
还是 " 满 " 。解决此问题的方法至少有三种:
( 1 )另设一个标志位区别队列的 " 空 " 和 " 满 "
( 2 )使用一个计数器记录队列中元素的总数(实际上是队列长度)。
( 3 )少用一个元素的空间,约定以 " 队列头指针在队列尾指针的下一位置(指环状的下一位置)上 ' ' 作为队列呈 " 满 " 状态的标志。(在后续算法中我们使用这种方法)
|
74.计算机组成原理王道最后8套题第四套第一,1题025页 1.若循环队列以数组Q[0...m-1]作为其存储结构,变量rear表示循环队列中的队尾元素的实际位置,其移动按rear -(rear+1) MOD m进行,变量length表示当前循环队列中的元素个数,则循环队列的队首元素的实际位置是()。 |
| A. rear-length |
| B. (rear-length+m) MOD m |
| C. (1+rear+m-length) MOD m |
| D. (rear+length-1) MOD m |
| C |
| 1.C。 [解析]考直循环队列的性质。区分循环队列队空还是队满有3种方法:①牺牲个存储单元:②增设表示元素个数的变量:③设标记法。这里用的是第一种方法。因为元素移动按rear一(rear+1)MOD m进行,即若队列没有循环时(即队列没有越过数组的头尾),队头应该在队尾的左侧,即数组下标小的位置,详细来算应当是数组下标为rear (ength 1)的位置(因为Qfrear]本身占用一个位置,所以减去的长度不是length,而是length -1),然而光是这样若队列越过了数组头尾,那么会导致算出来的队头为负数,所以这里可以给这个式子加上一个数组长度再取模,即(rear-length-1+m) MOD m,这样当队列没有越过数组边界时,由于取模的存在,能保证结果的正确,而当队列越过了数组边界时,由于加了m所以结果正确。 [另解]特殊值代入法:对于循环队列,A和D无取MOD操作,显然错误,直接排除。设length等于1,rear 等于0,代入BC两项,显然仅有C符合。 |
循环队列中需要注意的几点.
( 1 )如果 Q.front= Q.rear ,则可以判断循环队列为空
( 2 )如果 (Q.rear+1)%MAXQSIZE==Q.front ,则可以判断循环队列为满。
( 3 )无论是对循环队列进行插入或删除元素时,均可能涉及到尾指针或头指针的调整(非简单地对指针进行+ 1 操作),即
入队:Q.rear=(Q.rear+1)%MAXQSIZE 或
出队:Q.front=(Q.front+1)%MAXQSIZE
( 4 )如何理解
(Q.rear-Q.front+ MAXQSIZE)%MAXQSIZE
即为循环队列的长度
当 Q.rear>Q.front 时,循环队列长度 =Q.rear-Q.front ;
当 Q.rear< Q.front 时,循环队列长度:( Q.rear ,Q.front+ MAXQSIZE)
综合考虑以上两种情况,循环队列长度(任何情况下)=(Q.rear-Q.front+ MAXQSIZE)%MAXQSIZE
(5)算实际元素
例如
Max=5
f=1 r=4⟹3
f=4 r=1⟹2
公式 (Q.rear-Q.front+Max)%Max
循环队列(Circular Queue) 总结
存储队列的数组被当作首尾相接的表处理。
队头、队尾指针加1时从maxSize -1直接进到0,可用语言的取模(余数)运算实现。
队头指针进1: Q.front = (Q.front + 1)% MAXSIZEA 队尾指针进1: Q.rear= (Q.rear+ 1)% MAXSIZE;
队列初始化: Q.front = Q.rear- 0;
队空条件: Q.front =Q.rear;
队满条件: (Q.rear+ 1) % MAXSIZE = Q.front
队列长度: (Q.rear-Q.front+MAXSIZE)%MAXSIZE
最后一个图不知道满还是空,以牺牲一个元素作为满的条件,这样就区分了满和空
说明
“不能用动态分配的一维数组来实现循环队列,初始化时必须设定一个最大队列长度。
循环队列中要有一个元素空间浪费掉
解决Q.front=Q.rear不能判别队列“空”还是“满"
办法:
使用一个计数器记录队列中元素的总数(即队列长度)
设一个标志变量以区别队列是空或满
队列(包括循环队列)是一个逻辑概念,而链表是一个存储概念。一个队列是否是循环队列,不取决于它将采蒯可种存储结构,根据实际的需要,循环队列可以采用顺序存储结构,也可以采用链式存储结构,包括采用循环链表作为诸结构。
( 1 )一串数据依次通过一个栈,可以产生多种出栈序列。可能的不同出栈序列数目的计算可利用 Catalan 函数算出。
\(\frac{1}{n+1}C_{2n}^{n}\)
例如:卡特兰数,14种出栈序列
\(\frac{1}{n+1}C_{2n}^{n} = \frac{1}{4+1}C_{8}^{4}=14\)
一串数据通过一个栈后的次序由每个数据之间的入栈、出栈操作序列决定,只有当所有数据 " 全部入栈后再全部出栈 " 才能使数据倒置。事实上,存在一种操作序列 " 入栈、出栈、入栈、出栈一一 " 可以使数据通过栈后仍然保持次序不变。
( 2 )一串数据通过一个队列,只有一种出队列顺序,就是其入队列顺序。
|
9.数据结构王道考研第三章:线性表.第二节:队列第76页,第一,6题 6.已知循环队列的存储空间为A[21],front指向对头元素的前一个位置,rear指向队尾元素,假设当前front和rear的值分别是8和3则该对列的长度为() |
| A.5 |
| B.6 |
| C.16 |
| D.17 |
| C |
| 6.C队列的长度为 (rear-front+maxsize)%maxsize=(rear-front+21)%21 =(3-8+21)%21=16, 这种情况front指向当前元素,rear指向对位元素的下一个元素的计算是相同的. |
|
新东方赵海英习题 5. 若用一个大小为6的数组来实现循环队列,且当前rear和front的值分别 为0和3,当从队列中删除一个元素,再加入两个元素后,rear和 front的值分别为多少? |
| A. 1和 5 |
| B. 2和4 |
| C. 4和2 |
| D. 5和1 |
| B |
| B.删除一个元素后,队首指针要加1,front=(front+1)%6,结果为4,每加入一个元素队尾指针加一,即real=(real+1)%6,加入两个元素后变为2,所以选A删除动front,进队动rear. |
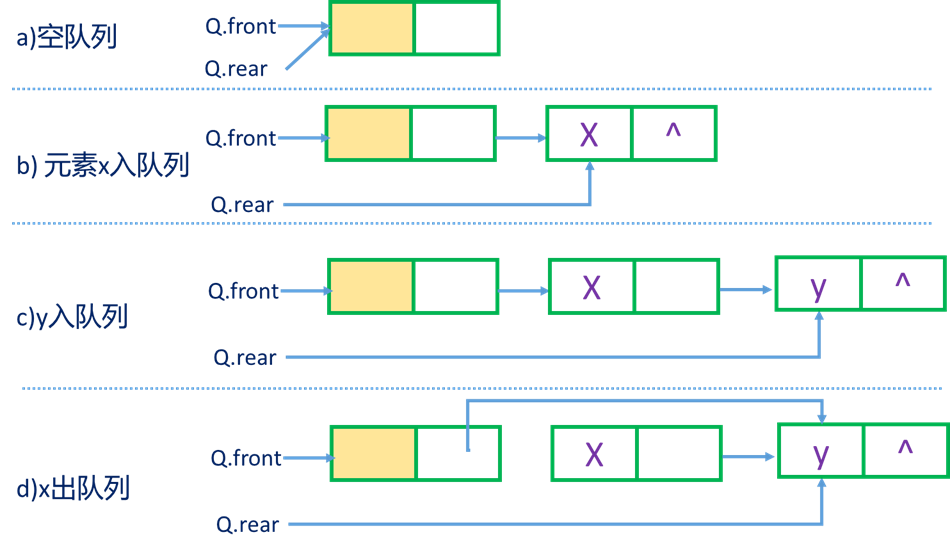
若用户无法估计所用队列的长度,则宜采用链队列

//链队列的类型定义
|
|
链队列运算指针变化状况(入队从后,出队从前)
评论列表 (0 条评论)