第二章线性表


逻辑结构
线性结构→线性表
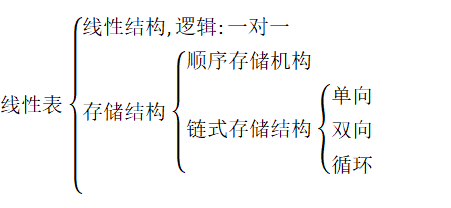
考研→线性表→定义存储→组合操作
存储结构结构→顺序表(连续的)
线性结构的特点:
在数据元素的非空有限集中
1)有且仅有一个开始结点;
2)有且仅有一个终端结点;
3)除第一个结点外,集合中的每个数据元素均有且只有一个前驱;
4)除最后一个结点外,集合中的每个数据元素均有且只有一个后继。
- 线性序列:线性结构中的所有结点按其关系可以排成一个序列,记为 (a1,…, ai, ai+1,...,an )
1)线性表是n(n ≥0)个数据元素的有限序列。
2)线性表是一种最常用且最简单的数据结构。
含有n个数据元素的线性表是一个数据结构:
List = (D,R)
其中:D = {ai | ai ∈D0 ,i=1,2,…n,n≥0}
R = {N}, N = {< ai-1, ai > | ai-1,ai ∈D 0 , i = 2,3,…n}
D 0 为某个数据对象——数据的子集
- 特性:均匀性,有序性(线性序列关系)
3)线性表的长度及空表
- 线性表中数据元素的个数n(n≥0)定义为线性表的长度当线性表的长度为0 时,称为空表。
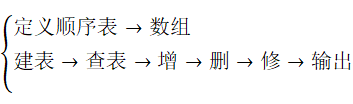
2.1 线性表的类型定义
- 当线性表的长度为0 时,称为空表。
- ai 是第i个数据元素,称i为ai 在线性表中的位序。
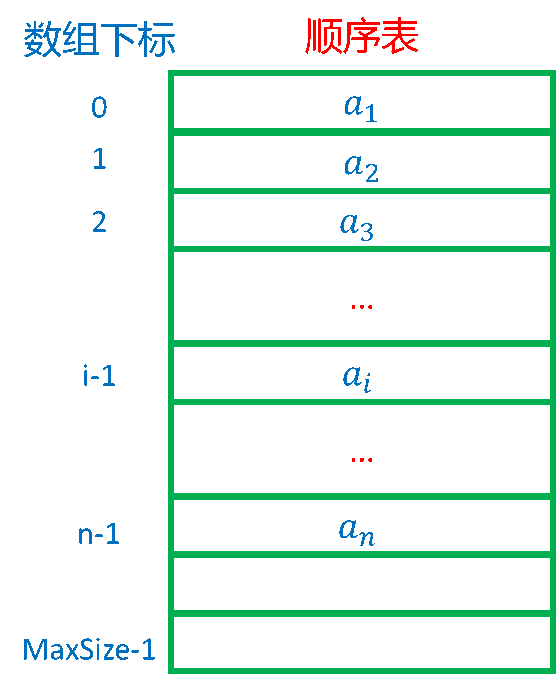
顺序表的示意图
#define MAXSIZE 100
typedef struct{
ElemType *elem
int length;
}Sqlist; //定义顺序表类型
Sqlist L;//定义变量L,L是SqList这种类型的,L是个顺序表

|
23.数据结构王道考研第一章:绪论.第一节:数据结构的基本概念第4页,第7题 7.链式存储设计时,结点内的存储单元地址() |
| A.一定连续 |
| B.一定不连续 |
| C.不一定连续 |
| D .部分连续,部分不连续。 |
| A |
A,链式存储设计时,各个不同结点的存储空间可以不连续,但是结点内的存储单元地址则必须连续。
|
23.数据结构王道考研第一章:绪论.第一节:数据结构的基本概念第4页,第二.2题
试举一例,说明对相同的逻辑结构,同一种运算在不同的存储方式下实现,其运算效率不同
线性表既可以用顺序存储方式实现,也可以用链式存储方式实现。在顺序存储方式下,表中插入和删除元素,平均要移动近一半的元素,时间复杂度为o(n).
 在链式存储下,插入删除的时间复杂度是o(1).
在链式存储下,插入删除的时间复杂度是o(1).

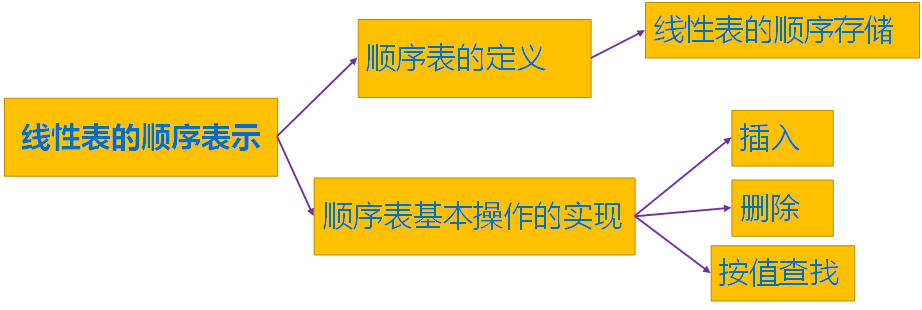
1)InitList(&L) 初始化,构造一个空的线性表
2)ListLength(L) 求长度,返回线性表中数据元素个数
3)GetElem(L,i,&e) 取表L中第i个数据元素赋值给e
4)LocateElem(L,e) 按值查找,若表中存在 个或多个值为e的结点,返回第一个找到的数据元素的位序,否则返回一个特殊值。
5)ListInsert(&L,i,e) 在L中第i个位置前插入新的数据元素e,表长加1。
6)ListDelete(&L,i,e) 删除表中第i个数据元素,e返回其值,表长减1。
①插入
 |
|
ListInsert(L, 3, 'e') //第三个元素插入一个e

pi=1/(n+1) ∑pi(n-i+1)=n/2
时间复杂度为o(n)
②删除
|
|
ListDelete (L, 3, e) //删除第三个元素
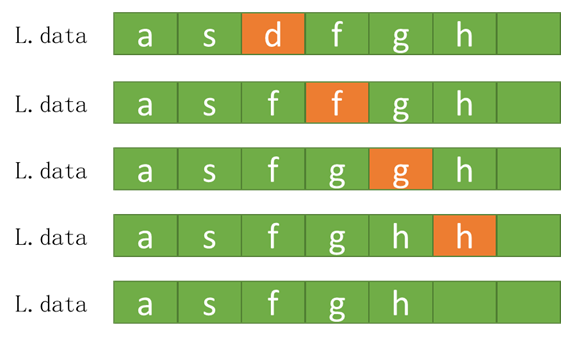
pi=1/(n+1) ∑𝑝𝑖𝑛−𝑖=(𝑛−1)/2
时间复杂度o(n)
③按值查找
查找没有修改值,所以不用引用&
|
|
查找到头没有找到返回0,为什么i+1时从0开始的
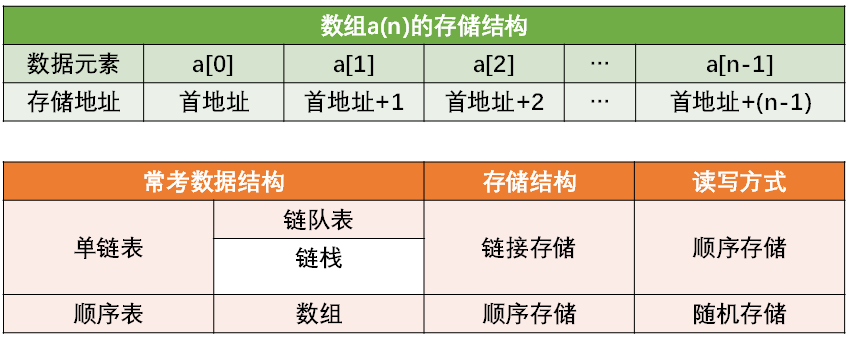
- 用“物理位置”相邻来表示线性表中数据元素之间的逻辑关系。
顺序表—线性表的顺序存储结构
- 根据线性表的顺序存储结构的特点,只要确定了存储线性表的起始位置,线性表中任一数据元素都可随机存取,所以,线性表的顺序存储结构是一种随机存取的存储结构
|
3.数据结构王道考研第二章:线性表.第二节:线性表的顺序表示第18页,第二,10题 线性表的顺序存储结构是一种( )。 |
| A.随机存取的存储结构 |
| B .顺序存取的存储结构 |
| C .索引存取的存储结构 |
| D .散列存取的存储结构 |
| A |
|
A.存=写,取=读 考查的是读写方式(随机、顺序) 不是存储方式(顺序、链接、索引、散列) 顺序表用一组连续的存储单元,依次存储数据元素。 可用下面公式实现随机存取: 目标地址=首地址+单元长度*单元序号 |
|
4.数据结构王道考研第二章:线性表.第三节:线性表的顺序表示链式表示第35页,第二,4题
下列关于线性表说法正确的是( )。 I .顺序存储方式只能用于存储线性结构 II .取线性表的第i个元素的时间与i的大小有关 III.静态链表需要分配较大的连续空间,插入和删除不需要移动元素 IV .在一个长度为n的有序单链表中插入一个新结点并仍保持有序的时间复杂度为O(n) V .若用单链表来表示队列,则应该选用带尾指针的循环链表 |
| A.I、II |
| B.I、III、IV、V |
| C. IV、 V |
| D.III、IV、V |
| D |
|
解:顺序存储方式同样适合图和树的存储,如满二叉树的顺序存储,I 错误。
选D.若线性表采用顺序存储方式,则取其第i个元素的时间与i的大小无关,II 错误。 III是静态链表的特有性质,III 正确。 单链表只能顺序查找插入位置,时间复杂度为0(n),若为顺序表,可采用折半查找,时间复杂度可降至0(log;n),IV 正确。
队列需要在表头删除元素,表尾插入元素,故采用带尾指针的循环单链表较为方便,插入和删除的时间复杂度都是o(1),V正确。
|



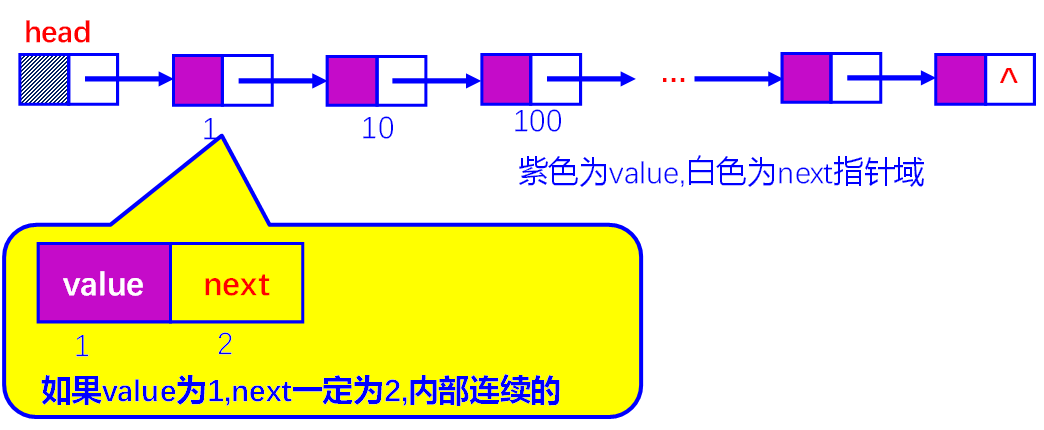
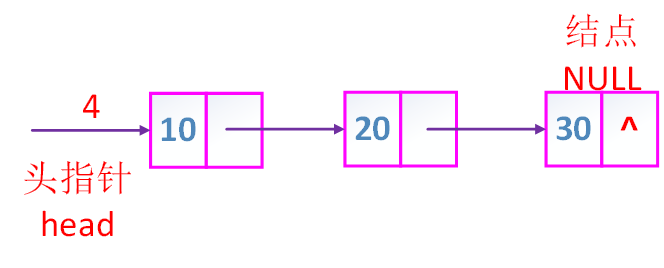
1. 线性链表
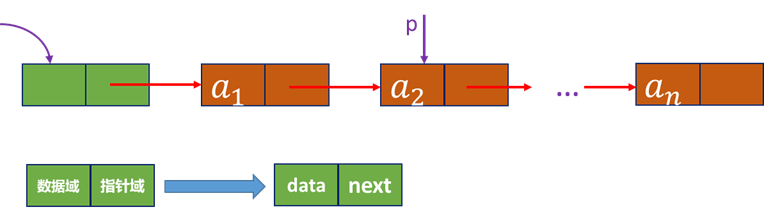
- 特点:在内存中用一组任意的存储单元来存储线性表的数据元素,用每个数据元素所带的指针来确定其后继元素的存储位置。这两部分信息组成数据元素的存储映像,称作结点。
结点。
- 结点:数据域 + 指针域(链域)
- 链式存储结构:n个结点链接成一个链表
- 线性链表(单链表):链表的每个结点只包含一个指针域
对含有n个记录得到表,查找成功时:

顺序查找的平均查找长度:
ASL = P1+2P2+…+(n-1)P𝑛−1+nP𝑛
假设每个记录的查找概率相等:
不连续的三个元素10 20 30
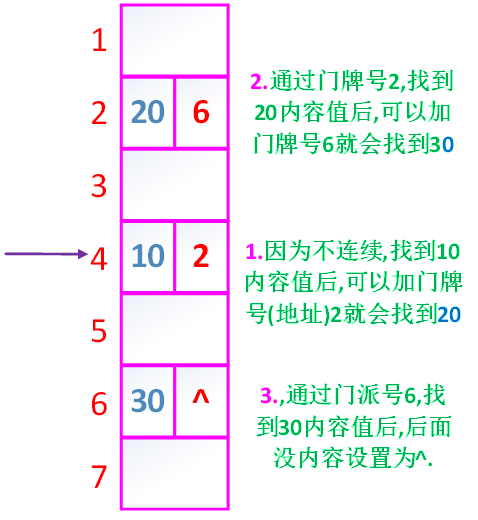
如果插入元素15如图
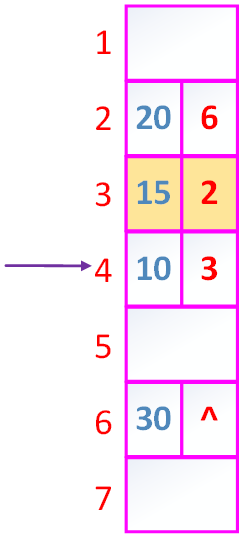
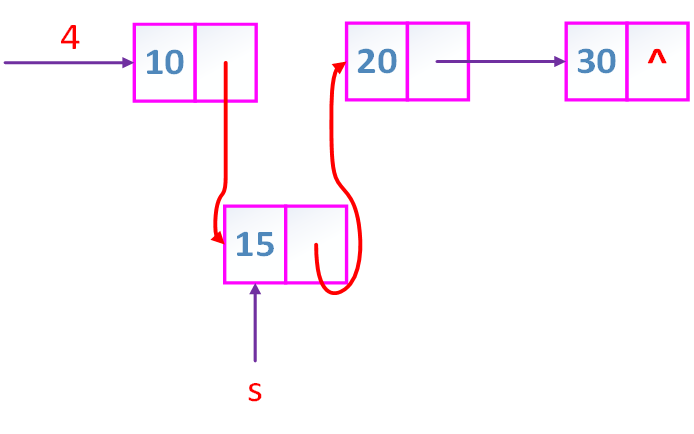

如果删除20
①
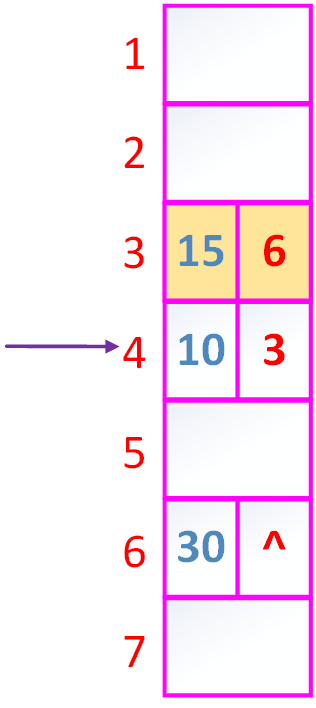
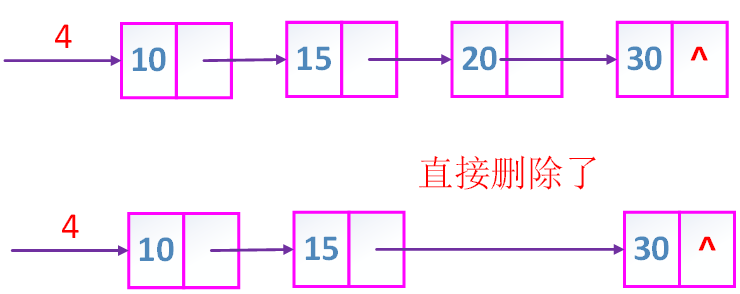
可见删除元素很方便
缺点不能访问挨着的前一个节点,后面节点没有前一个节点的地址(问牌号),只有前一个节点有后一个节点的地址.必须从头开始访问,叫顺序访问.
顺序存储是随机访问,链式存储是顺序访问.
typdef struct node //声明结点的类型和指向结点的指针类型
{
ElemType data ;// 结点的数据域
struct node *next;//指向自身的指针域
} Lnode, *LinkList //LinkList为指向结构体Lnode的指针类型
|
适用于链表的查找方法是 |
| A.顺序 |
| B.二分法 |
| C.顺序,也能二分法 |
| D.随机 |
| A |
|
正确答案 答案解析 |
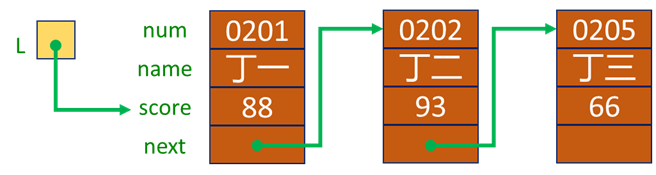
例如,存储学生学号、姓名、成绩的单链表结点类型定义如下:
typedef Struct student{
char num[8]; //数据域
char name[8]; //数据域
int score; //数据域
struct students* next; //指针域
}Lnode, * LinkList;
为了统一链表的操作,通常这样定义:
typedef Struct student{
ElemType data; //数据域
struct * next; //指针域
}Lnode, * LinkList;
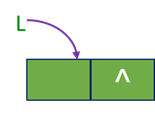
■单链表的初始化(算法2.6)(带头结点的单链表)
■即构造一个如图的空表
[算法步骤]
(1)生成新结点作头结点,用头指针L指向头结点。
(2)将头结点的指针域置空。
[算法描述]
Status InitList_L(LinkList &L)
{
L = new Lnode;
L->next = NULL;
return OK;
}
补充单链表的几个常用简单算法
[补充算法1]一判断链表是否为空:
空表:链表中无元素上称为空链表(头指针和头结点仍然在)
[算法思路]判断头结点指针域是否为空
若L是空表 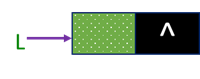
int ListEmpty(LinkList L) //若L为空表,否则返回0
{
if (L->next) //非空
return 0;
else
return 1;
}
■[补充算法2]一单链表的销毁: 链表销毁后不存在
[算法思路]从头指针开始,依次释放所有结点
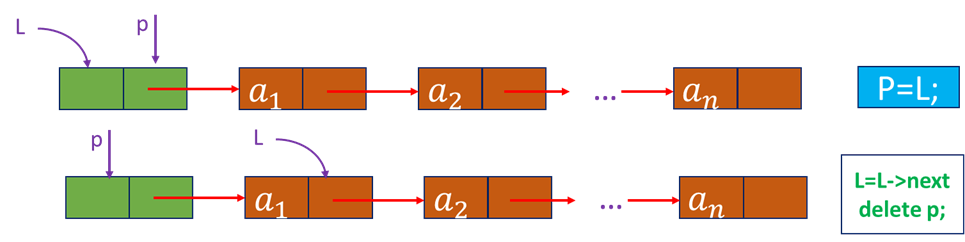
如果用delete前面用new,如果free前面用malloc

Status InitList_L(LinkList& L) //销毁单链表L
{
L = new Lnode; //或LinkList p;
while (L)
{
p = L;
L = L->next;
delete p;
}
return OK;
}
■[补充算法3]--清空链表:
链表仍存在,但链表中无元素,成为空链表(头指针和头结点仍然在)
[算法思路]依次释放所有结点,并将头结点指针域设置为空
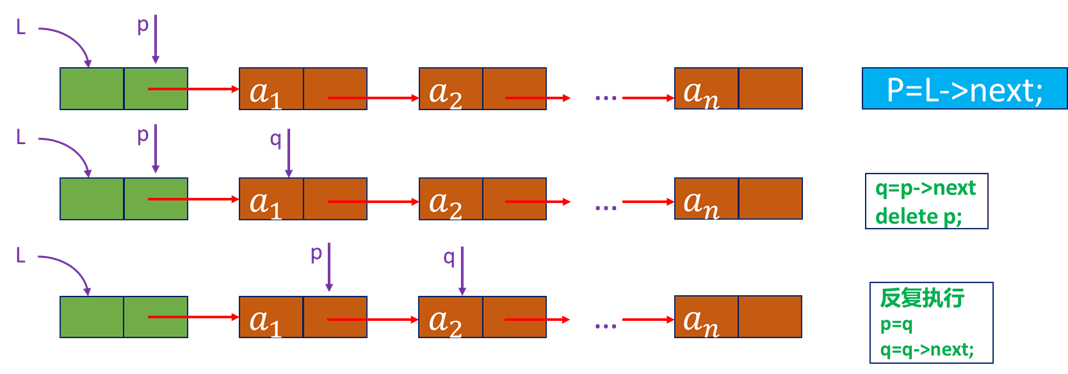

Status InitList_L(LinkList& L) //将L重置为空表
{
Lnode *p, *q; //或LinkList p,q;
p = L->next;
while (p) //没到表尾
{
q = p->next;
delete p;
p = q;
}
L->next = NULL; //头结点指针域为空
return OK;
}
[补充算法4] -求单链表的表长
[算法思路]从首元结点开始,依次计数所有结点

int ListLength_L(LinkList) //返回L中数据元素的个数
{
LinkList P;
p = L->next; //p指向第一个结点
i = 0;
while (p) //遍历单链表,统计结点数
{
i++;
p = p->next;
}
return i;
}
[算法2.7]取值一取单链表中第i个元素的内容
[算法思路]
分别取出表中第3个元素和第15个元素 i=3 i=15 i= -1
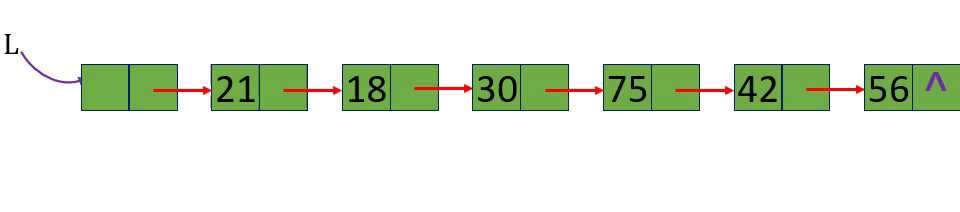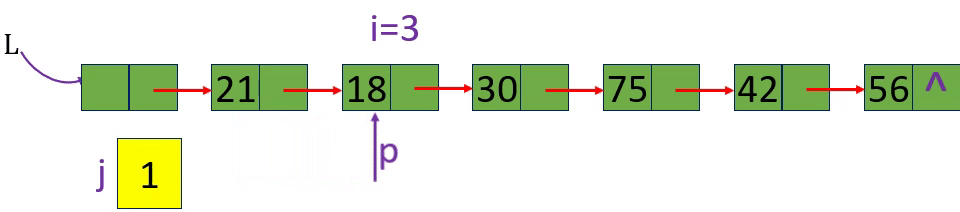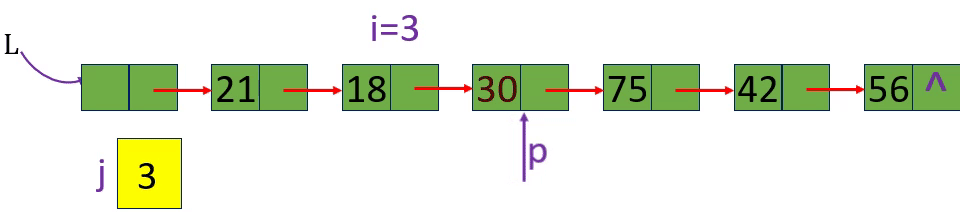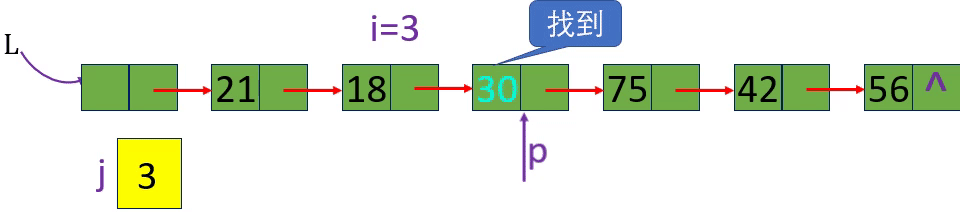
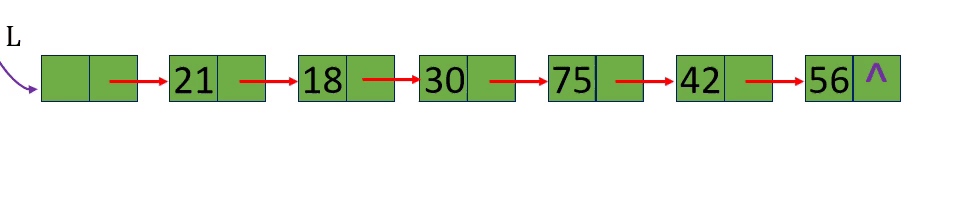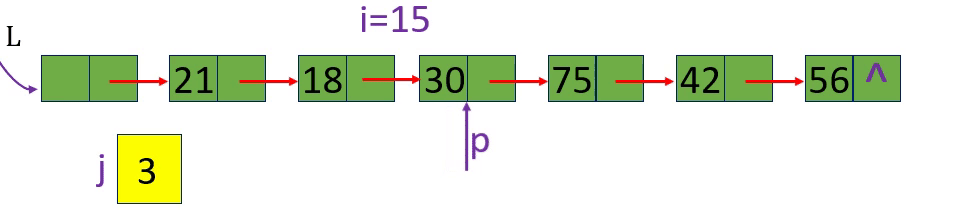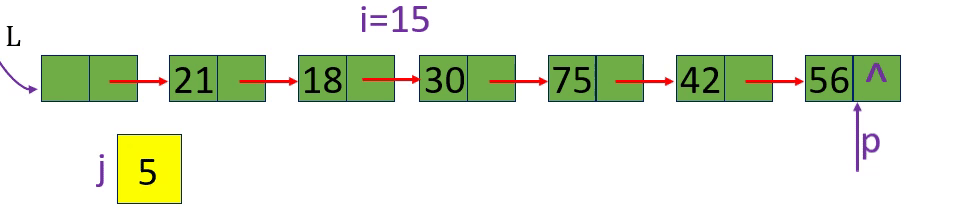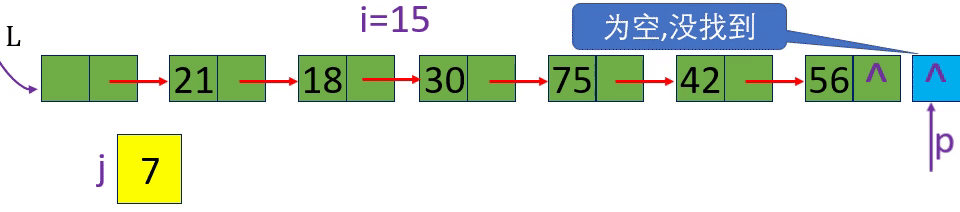
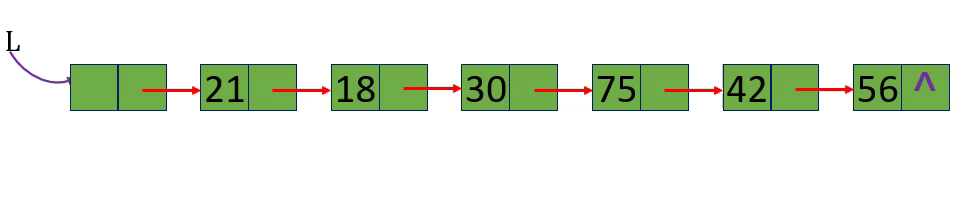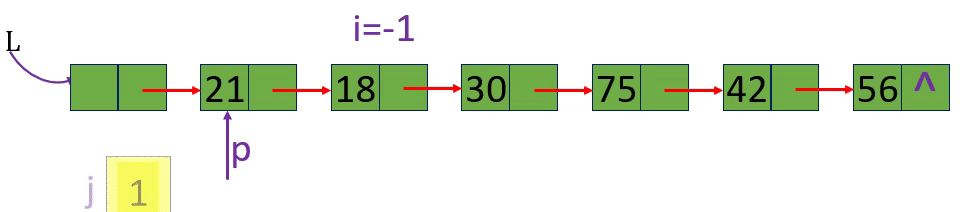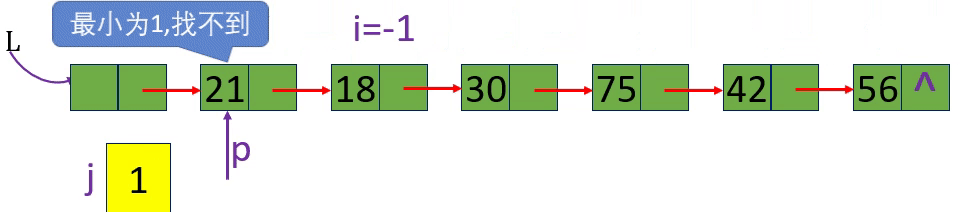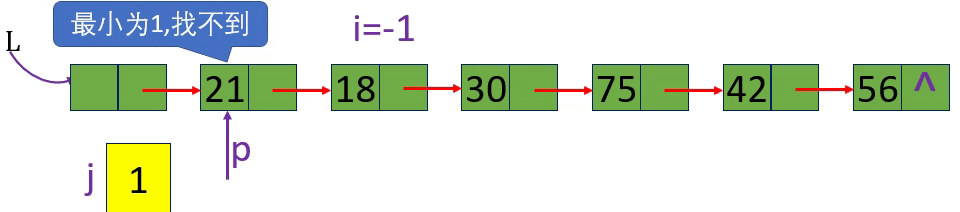
从链表的头指针出发,顺着链域next逐个结点往下搜索,直至搜索到第i个结点为止。因此,链表不是随机存取结构
[算法步骤]
1.从第1个结点(L->next) 顺链扫描,用指针p指向当前扫描到的结点,p初值p= L->next。
2. j做计数器,累计当前扫描过的结点数, j 初值为1.
3.当p指向扫描到的下一结点时,计数器j加1。
4.当j== i时,p所指的结点就是要找的第i个结点。
Staus GetElem L(LinkList L, int i, ElemType& e)
{//获取线性表L中的某个数据元素的内容,通过变量e返回
p = L->next; j = 1; //初始化
while (p && j < i) //向后扫描,直到p指向第i个元素或p为空
{
p = p->next; ++j;
}
if (!p || j > i) return ERROR; //第i个元素不存在
e = p->data; //取第i个元素
return OK;
} //GetElem_L
[算法2.8]按值查找一根据指定数据获取该数据所在的位置 (地址)
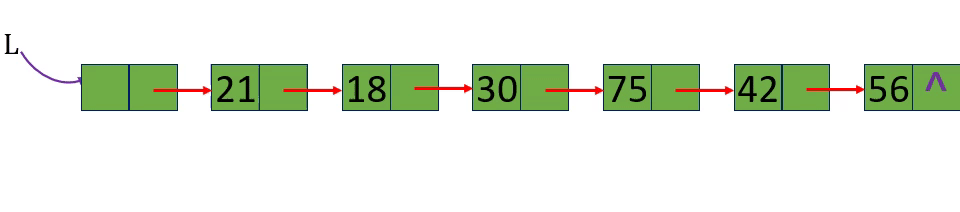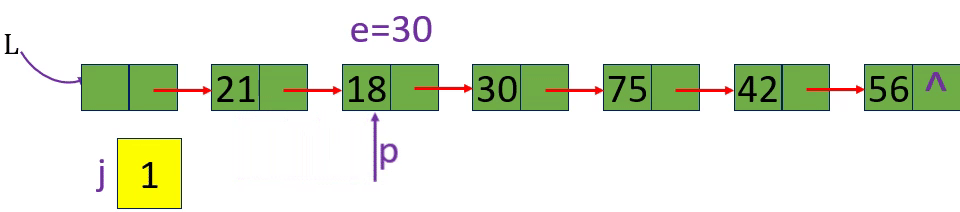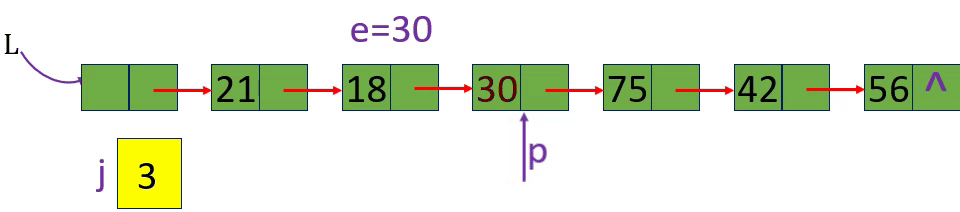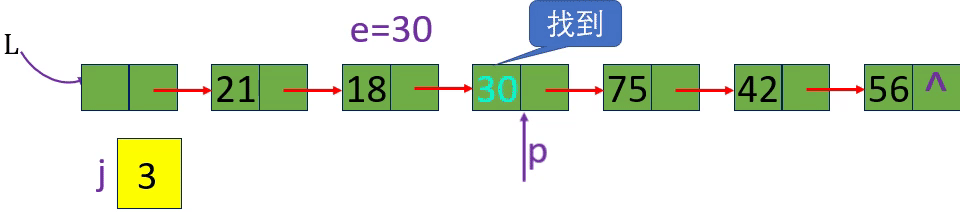
p=L-> next; p=p-> next; p->data!=e
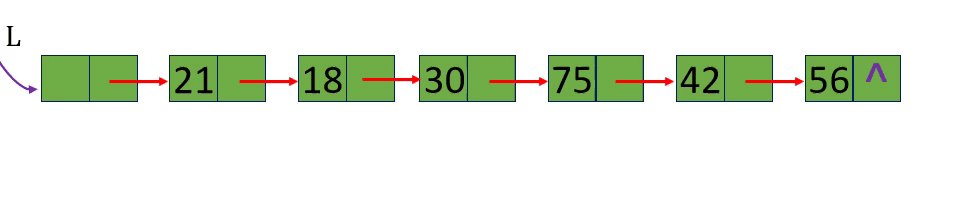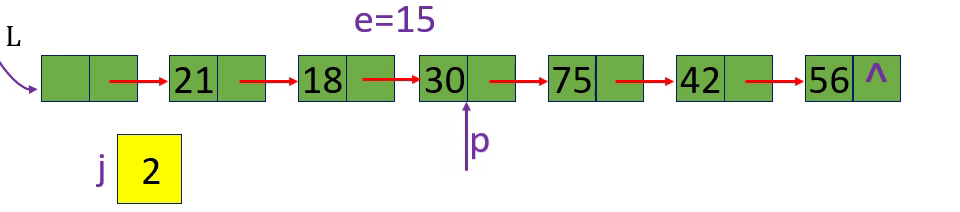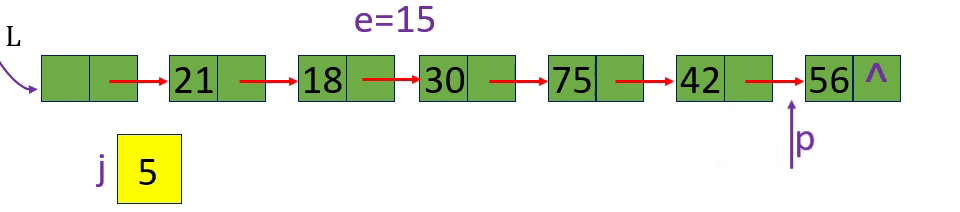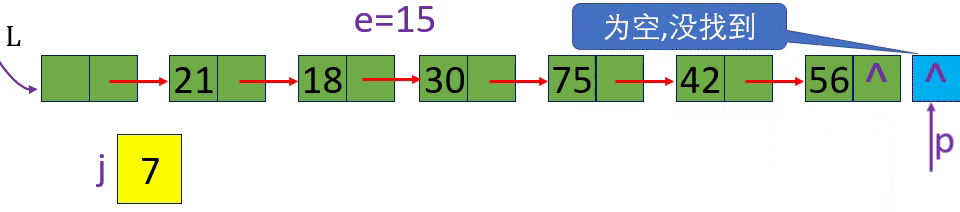
p=L-> next; p=p-> next; p->data!=e; p!=NULL或p
未找到返回0
//将线性表L中第i个数据元素删除
Status ListDelete_L(LinkList& L, int i, ElemType& e) {
p = L; j = 0;
while (p->next && j < i - 1) { p = p->next; ++j; }
//寻找第i个结点,并令p指向其前驱
if (!(p->next) || j > i - 1) return ERROR; //删除位置不合理
q = p->next; //临时保存被删结点的地址以备释放
p->next = q->next; //改变删除结点前驱结点的指针域
e = q->data; //保存删除结点的数据域
delete q; //释放删除结点的空间
return OK;
}//ListDelete_L
描述以下三个概念的区别:头指针,头结点,首元结点(第一个元素结点)。
头指针是指向链表中第一个结点的指针。头结点是在首元结点之前附设的一个结点,该结点不存储数据元素,其指针域指向首元结点,其作用主要是为了方便对链表的操作,它可以对空表、非空表以及首元结点的操作进行统一处理。首元结点是指链表中存储第一个数据元素的结点。
| 7、链接存储的存储结构所占存储空间() |
| A.分两部分,一部分存放结点值,另一部分存放表示结点间关系的指针 |
| B.只有一部分,存放结点值 |
| C.只有一部分,存储表示结点间关系的指针 |
| D.分两部分,一部分存放结点值,另一部分存放结点所占单元数 |
| A |
| 选A |
|
链表不具有的特点是( )。 |
| A.不必事先估计存储空间 |
| B.可随机访问任一元素 |
| C.插入删除不需要移动元素 |
| D.所需空间与线性表长度成正比 |
| B |
正确答案B 答案解析链表采用的是链式存储结构,它克服了顺序存储结构的缺点:它的结点空间可以动态申请和释放;它的数据元素的逻辑次序靠结点的指针来指示,不需要移动数据元素。但是链式存储结构也有不足之处:①每个结点中的指针域需额外占用存储空间;②链式存储结构是一种非随机存储结构。 |
2.3.3 单链表操作
1.创建链表
struct node *p1, *p2,*p3;
p1=new node;
p1->data=a1
p2=new node;
p2->data=p2
p1->next=p2
p2->next=p1
//但是创建很多时用for循环.
创建链表两种方式
①栈式创建(前插:p2->next=p1)
②队式创建(后插:p1->next=p2)
2.链表查询\(\left\{\begin{matrix} {序号}\\{数据} \end{matrix}\right.\)
作为链表,头结点不能乱动,不然乱了,

if(p0->data==a3)
//判断p0的数据是否等于a3的数据
while (p0->data!=a3)
p0=p0->next
3.链表的插入
①头插法

void CreateList_H(LinkList& L, int n)
{
L = new LNode;
L->next = NULL; //先建立一个带头结点的单链表
for (i = n; i > 0; i++)
{
p = new LNode; //生成结点
cin >> p->data; //输入元素值
p->next = L->next; //插入到表头
L->next = p;
}
}//CreateList_hH
②尾插法
[算法2.12]建立单链表:尾插法元素插入在链表尾部,也叫尾插法
1.从一个空表L开始,将新结点逐个插入到链表的尾部,尾指针r指向链表的尾结点。
2.初始时,r同L均指向头结点。每读入一个数据元素则申请一个新结点,将新结点插入到尾结点后,r指向新结点。
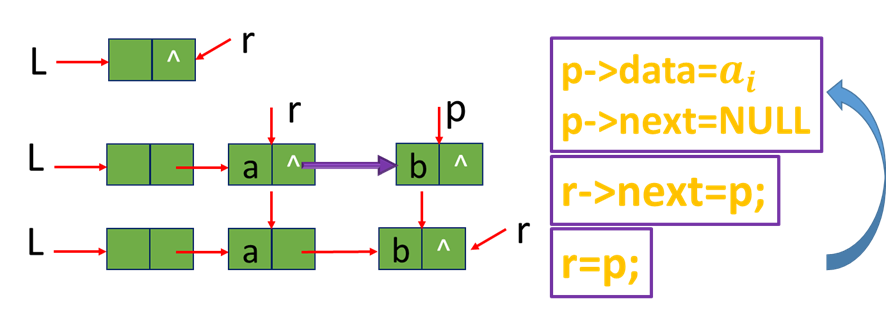
[算法描述]
//正位序输入n个元素的值, 建立带表头结点的单链衣L
void CreateList_R(LinkList& L, int n) {
L = new LNode;
L->next = NULL;
r = L; //尾指针r指向头结点
for (i = 0; i<n; ++i) {
p = new LNode; cin >> p->data; //生成新结点,输入元素值
p->next = NULL;
r->next = p; //插入到表尾
r = p; //r指向新的尾结点
}//CreateList R
//算法的时间复杂度是: O(n)
4.查找
|
|
5.链表的删除

while(p->next->data!=40)
p=p->next 两步循环找40结点
为什么是q->next->next,因为20节点为q->next所以30结点为q->next->next
如:
a、请将结点b从链表中删除。
b、请将结点d从链表中删除。
c、请将结点a从链表中删除并让head重新指向链表的第一个结点。

注:如果删头,头直接下移,要删除中间和尾部地址要知道删的结点前面结点的地址
删完之后要释放的.
循环列表每个结点都能找到
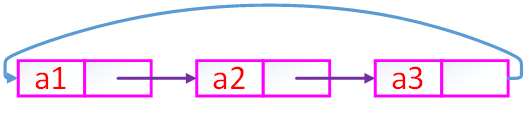
双向链表

既能找前驱又能找后继,缺点浪费空间
1)循环链表一是一种首尾相接的链表。
循环链表最后一个结点的next指针不为0(NULL),而是指向了表头结点。在循环链表中没有NULL为简化操作,在循环表中往往加入表头结点。
特点:循环链表中,从任一结点出都可访问到表中所有须从头指开始,否则无法访问到该节点之前的其他结点.
循环链表一单链表不同的是链表中表尾结点的指针域不是NULL,而是链表、结点的指针H(链表指针)
注意:
由于循环链表中没有NULL指针,故涉及遍历操作时,其终止条件就不再像非循环链表那样判断p或p- >next是否为空,而是判断它们是否等于头指针。
循环条件:
p!=NULL -> p!=L
p-> next!=NULL -> p->next!=L
单链表 单循环链表

\(头指针表示 单循环链表\begin{cases}找𝑎_1 的时间复杂度: \color{red}{0(1)}\\ 找𝑎_𝑛 的时间复杂度: \color{red}{0(n)}\\ \end{cases} \)不方便
注意:表的操作常常是在表的首尾位置上进行。
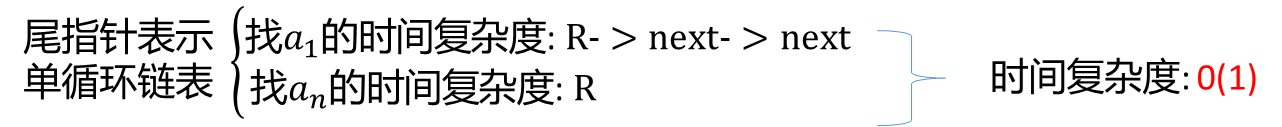

带尾指针循环链表的合并(将Tb合并在Ta之后)
分析有哪些操作?
● p存表头结点 ●Tb表头连接到Ta表尾 ●释放Tb表头结点 ●修改指针
p=Ta-> next; Ta->next= Tb->next-> next ; delete Tb-> next; Tb->next=p;
带尾指针循环链表的合并
[算法描述]
LinkList Connect(LinkList Ta, LinkList Tb) {
//假设Ta、Tb都是非空的单循环链表
p = Ta->next; //①p存表头结点
Ta->next = Tb->next->next; //②Tb表头连结Ta表尾
delete Tb - > next; //③释放Tb表头结点
Tb->next = p; . //④修改指针
return Tb;
}
在一个头指针为L的循环链表中,指针域为next,指针P所指结点(此结点是尾结点)的条件是______。
P->next==L
用尾指针rear表示的单循环链表对开始结点a1和终端结点查找时间都是O(1)。而表的操作常常是在表的首尾位置上进行,因此,实用中多采用尾指针表示单循环链表。
注意:判断空链表的条件为rear==rear->next;

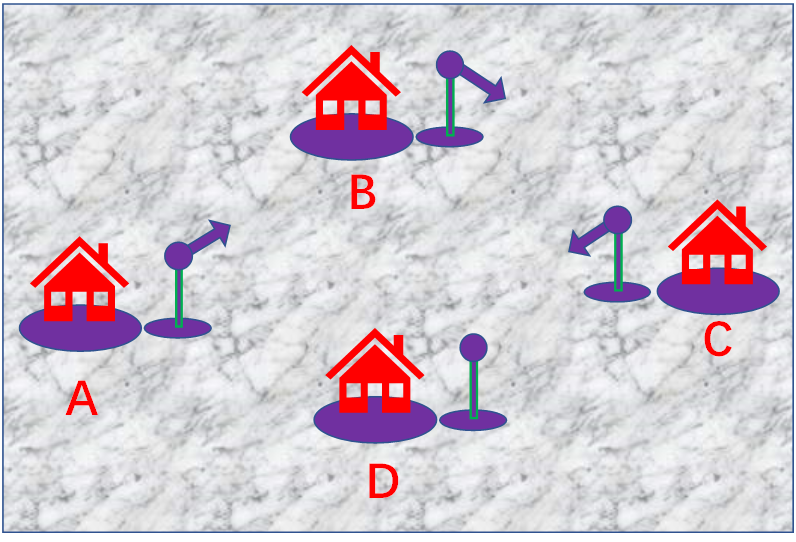
每个旁边插个方向指示标,让它指向前面一个房子,
就变成双链表
到双向链表是指在前驱和后继方向都能游历(遍历)的线性链表。
1)双向链表的结点结构:
前驱方向⟵(a)结点结构⟶后继方向
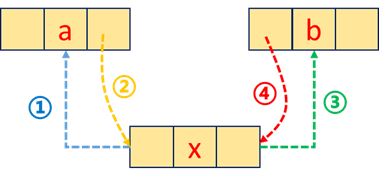
1.S-> prior=p-> prior;
2.p-> prior-> next=S;
3.S-> next= p;
4.p-> prior=S;
| 7 、静态链表中指针表示的是()。 |
| A .内存地址 |
| B.数组下标 |
| C .下一元素地址 |
| D .左、右孩子地址 |
| C |
| C.所谓静态链表就是没有指针的,用下标模仿这个指针的功能的 |
| 16.对于一个头指针为head的头结点的单链表,判定为空的条件是() |
| A. head==NULL |
| B. head->next==NULL |
| C.head->next==head |
| D. head! =NULL |
| B |
|
正确答案:B 在带头结点的单链表中,head指向头结点,由头结点的next域指向第1个元素结点,head->next=NULL表示该单链表为空。在不带头结点的单链表中,head直接指向第1个元素结点,head=NULL表示该单链表为空。 |
评论列表 (0 条评论)