ros小车(四)语音功能(乌班图18.04)
复制linux下文件到远程端,这是不需要用桌面操作,如果没有提前下载好,这步可以省略,后面有下载步骤
scp -r /home/yys/linux yyssz@192.168.31.204:/home/yyssz
正视开始安装
sudo apt-get install ros-melodic-audio-common libasound2
sudo apt-get install gstreamer0.10-*
这条要添加源,这个库不安装得话gstreamer0.10-pocketsphinx会装不上
sudo vim /etc/apt/sources.list
deb http://mirrors.ustc.edu.cn/ubuntu/ xenial main universe
sudo apt update
sudo apt-get install python-gst0.10
下面几个要按顺序安装,不然报错,安装套路相同
2.1安装libsphinxbase1,点击
选x86系统Linux,amd64得.
|
选择ftp.cn.debian.org/debian,
|
亞洲 |
进入安装包文件夹,使用安装命令
sudo dpkg -i libsphinxbase1_0.8-6_amd64.deb
2.2.安装libpocketsphinx1软件包:点击
sudo dpkg -i libpocketsphinx1_0.8-5_amd64.deb
2.3.安装gstreamer0.10-pocketsphinx软件包:点击
sudo dpkg -i gstreamer0.10-pocketsphinx_0.8-5_amd64.deb
如果报错
dpkg: 依赖关系问题使得 gstreamer0.10-pocketsphinx:amd64 的配置工作不能继续:
gstreamer0.10-pocketsphinx:amd64 依赖于 libgstreamer-plugins-base0.10-0 (>= 0.10.0);然而:
未安装软件包 libgstreamer-plugins-base0.10-0。
gstreamer0.10-pocketsphinx:amd64 依赖于 libgstreamer0.10-0 (>= 0.10.14);然而:
未安装软件包 libgstreamer0.10-0。
dpkg: 处理软件包 gstreamer0.10-pocketsphinx:amd64 (--install)时出错:
依赖关系问题 - 仍未被配置
在处理时有错误发生:
gstreamer0.10-pocketsphinx:amd64
没有安装python-gst0.10
sudo apt-get install python-gst0.10
cd ~/catkin_ws/src
git clone https://github.com/mikeferguson/pocketsphinx
如果已经有了文件
cp wake.lm ~/catkin_ws/src/pocketsphinx/demo/
cp wake.dic ~/catkin_ws/src/pocketsphinx/demo/
cp -r tdt_sc_8k/ ~/catkin_ws/src/pocketsphinx/demo/
4.1 下载hmm、lm、dic文件
hmm文件:下载
提取出下载的文件,将其中data.tar.xz/./usr/share/pocketsphinx/model/hmm/zh/下的tdt_sc_8k文件复制到voice_ws/src/pocketsphinx下的demo中。
lm、dic文件:下载
提取出下载的文件,将其中data.tar.xz/./usr/share/pocketsphinx/model/lm/zh_CN/下的mandarin_notone.dic文件复制到voice_ws/src/pocketsphinx下的demo中。
4.2 生成自己的dic、lm文件
6.2.1 创建command.txt文件
vim command.txt
文件内容示例:
小白
停下
前进
后退
左转
保存并退出
4.2.2 利用lmtool生成lm文件
进入: Sphinx Knowledge Base Tool 网站,点击选择文件如下图所示,选取command.txt文件进行编译,将生成的.lm文件重命名为wake.lm并复制到catkin_ws/src/pocketsphinx下的demo中。复制mandarin_notone.dic中与command.txt文件中词汇相同的词,并将command.txt重命名为wake.dic,并复制到voice_ws/src/pocketsphinx下的demo中。
wake.dic示例:
小白 x iao b ai
停下 t ing x ia
前进 q ian j in
后退 h ou t ui
左转 z uo zh uan

几个选择就是新增文件

5.1修改recognizer.py
vim ~/catkin_ws/src/pocketsphinx/nodes/recognizer.py
#!/usr/bin/env python
"""
recognizer.py is a wrapper for pocketsphinx.
parameters:
~lm - filename of language model
~dict - filename of dictionary
~mic_name - set the pulsesrc device name for the microphone input.
e.g. a Logitech G35 Headset has the following device name: alsa_input.usb-Logitech_Logitech_G35_Headset-00-Headset_1.analog-mono
To list audio device info on your machine, in a terminal type: pacmd list-sources
publications:
~output (std_msgs/String) - text output
services:
~start (std_srvs/Empty) - start speech recognition
~stop (std_srvs/Empty) - stop speech recognition
"""
import roslib; roslib.load_manifest('pocketsphinx')
import rospy
import pygtk
pygtk.require('2.0')
import gtk
import gobject
import pygst
pygst.require('0.10')
gobject.threads_init()
import gst
from std_msgs.msg import String
from std_srvs.srv import *
import os
import commands
class recognizer(object):
""" GStreamer based speech recognizer. """
def __init__(self):
# Start node
rospy.init_node("recognizer")
self._device_name_param = "~mic_name" # Find the name of your microphone by typing pacmd list-sources in the terminal
self._lm_param = "~lm"
self._dic_param = "~dict"
self._hmm_param = "~hmm"
# Configure mics with gstreamer launch config
if rospy.has_param(self._device_name_param):
self.device_name = rospy.get_param(self._device_name_param)
self.device_index = self.pulse_index_from_name(self.device_name)
self.launch_config = "pulsesrc device=" + str(self.device_index)
rospy.loginfo("Using: pulsesrc device=%s name=%s", self.device_index, self.device_name)
elif rospy.has_param('~source'):
# common sources: 'alsasrc'
self.launch_config = rospy.get_param('~source')
else:
self.launch_config = 'gconfaudiosrc'
rospy.loginfo("Launch config: %s", self.launch_config)
self.launch_config += " ! audioconvert ! audioresample " \
+ '! vader name=vad auto-threshold=true ' \
+ '! pocketsphinx name=asr ! fakesink'
# Configure ROS settings
self.started = False
rospy.on_shutdown(self.shutdown)
self.pub = rospy.Publisher('~output', String, queue_size=10)
rospy.Service("~start", Empty, self.start)
rospy.Service("~stop", Empty, self.stop)
if rospy.has_param(self._lm_param) and rospy.has_param(self._dic_param):
self.start_recognizer()
else:
rospy.logwarn("lm and dic parameters need to be set to start recognizer.")
def start_recognizer(self):
rospy.loginfo("Starting recognizer... ")
self.pipeline = gst.parse_launch(self.launch_config)
self.asr = self.pipeline.get_by_name('asr')
self.asr.connect('partial_result', self.asr_partial_result)
self.asr.connect('result', self.asr_result)
#self.asr.set_property('configured', True)
self.asr.set_property('dsratio', 1)
# Configure language model
if rospy.has_param(self._lm_param):
lm = rospy.get_param(self._lm_param)
else:
rospy.logerr('Recognizer not started. Please specify a language model file.')
return
if rospy.has_param(self._dic_param):
dic = rospy.get_param(self._dic_param)
else:
rospy.logerr('Recognizer not started. Please specify a dictionary.')
return
if rospy.has_param(self._hmm_param):
hmm = rospy.get_param(self._hmm_param)
else:
rospy.logerr('Recognizer not started. Please specify a dictionary.')
return
self.asr.set_property('lm', lm)
self.asr.set_property('dict', dic)
self.asr.set_property('hmm', hmm)
self.bus = self.pipeline.get_bus()
self.bus.add_signal_watch()
self.bus_id = self.bus.connect('message::application', self.application_message)
self.pipeline.set_state(gst.STATE_PLAYING)
self.started = True
def pulse_index_from_name(self, name):
output = commands.getstatusoutput("pacmd list-sources | grep -B 1 'name: <" + name + ">' | grep -o -P '(?<=index: )[0-9]*'")
if len(output) == 2:
return output[1]
else:
raise Exception("Error. pulse index doesn't exist for name: " + name)
def stop_recognizer(self):
if self.started:
self.pipeline.set_state(gst.STATE_NULL)
self.pipeline.remove(self.asr)
self.bus.disconnect(self.bus_id)
self.started = False
def shutdown(self):
""" Delete any remaining parameters so they don't affect next launch """
for param in [self._device_name_param, self._lm_param, self._dic_param]:
if rospy.has_param(param):
rospy.delete_param(param)
""" Shutdown the GTK thread. """
gtk.main_quit()
def start(self, req):
self.start_recognizer()
rospy.loginfo("recognizer started")
return EmptyResponse()
def stop(self, req):
self.stop_recognizer()
rospy.loginfo("recognizer stopped")
return EmptyResponse()
def asr_partial_result(self, asr, text, uttid):
""" Forward partial result signals on the bus to the main thread. """
struct = gst.Structure('partial_result')
struct.set_value('hyp', text)
struct.set_value('uttid', uttid)
asr.post_message(gst.message_new_application(asr, struct))
def asr_result(self, asr, text, uttid):
""" Forward result signals on the bus to the main thread. """
struct = gst.Structure('result')
struct.set_value('hyp', text)
struct.set_value('uttid', uttid)
asr.post_message(gst.message_new_application(asr, struct))
def application_message(self, bus, msg):
""" Receive application messages from the bus. """
msgtype = msg.structure.get_name()
if msgtype == 'partial_result':
self.partial_result(msg.structure['hyp'], msg.structure['uttid'])
if msgtype == 'result':
self.final_result(msg.structure['hyp'], msg.structure['uttid'])
def partial_result(self, hyp, uttid):
""" Delete any previous selection, insert text and select it. """
rospy.logdebug("Partial: " + hyp)
def final_result(self, hyp, uttid):
""" Insert the final result. """
msg = String()
msg.data = str(hyp.lower())
rospy.loginfo(msg.data)
self.pub.publish(msg)
if __name__ == "__main__":
start = recognizer()
gtk.main()
5.2 修改voice_cmd.launch
(voice_cmd_vel.py是语音控制的, ros_arduino_python是控制小车的)
vim ~/catkin_ws/src/pocketsphinx/demo/voice_cmd.launch
<launch>
<node name="recognizer" pkg="pocketsphinx" type="recognizer.py" output="screen">
<param name="lm" value="$(find pocketsphinx)/demo/wake.lm"/>
<param name="dict" value="$(find pocketsphinx)/demo/wake.dic"/>
<param name="hmm" value="$(find pocketsphinx)/demo/tdt_sc_8k"/>
</node>
<node name="voice_cmd_vel" pkg="pocketsphinx" type="voice_cmd_vel.py" output="screen"/>
<node name="arduino" pkg="ros_arduino_python" type="arduino_node.py" output="screen">
<rosparam file="$(find ros_arduino_python)/config/my_arduino_params.yaml" command="load" />
</node>
</launch>
如果运行launch会报错
roslaunch pocketsphinx voice_cmd.launch
报错1
ImportError: No module named gtk
解决办法
sudo apt-get install python-gtk2 python-gtk2-dbg python-gtk2-dev python-gtk2-doc
报错2
Traceback (most recent call last):
File "/home/yys/catkin_ws/src/pocketsphinx/nodes/recognizer.py", line 185, in <module>
start = recognizer()
File "/home/yys/catkin_ws/src/pocketsphinx/nodes/recognizer.py", line 74, in __init__
self.start_recognizer()
File "/home/yys/catkin_ws/src/pocketsphinx/nodes/recognizer.py", line 81, in start_recognizer
self.pipeline = gst.parse_launch(self.launch_config)
glib.GError: no element "audioconvert"
Traceback (most recent call last):
File "/opt/ros/melodic/lib/python2.7/dist-packages/rospy/core.py", line 568, in signal_shutdown
h()
File "/home/yys/catkin_ws/src/pocketsphinx/nodes/recognizer.py", line 139, in shutdown
gtk.main_quit()
RuntimeError: called outside of a mainloop
解决办法(这个库第二次装了,不知道为什么可以解决)
sudo apt-get install ros-melodic-audio-common libasound2
sudo apt-get install gstreamer0.10-*
警告1
Failed to load module "canberra-gtk-module"
sudo apt-get install libcanberra-gtk-module
警告2(win10 wubantu18.04子系统)
(recognizer.py:14176): GConf-WARNING **: 12:52:37.090: Client failed to connect to the D-BUS daemon:
Unable to autolaunch a dbus-daemon without a $DISPLAY for X11
eval `dbus-launch --sh-syntax`
roslaunch pocketsphinx voice_cmd.launch
成功页面
[INFO] [1601811715.013048]: 停下
INFO: ngram_search_fwdtree.c(1549): 572 words recognized (6/fr)
INFO: ngram_search_fwdtree.c(1551): 7123 senones evaluated (74/fr)
INFO: ngram_search_fwdtree.c(1553): 2536 channels searched (26/fr), 460 1st, 1201 last
INFO: ngram_search_fwdtree.c(1557): 677 words for which last channels evaluated (7/fr)
INFO: ngram_search_fwdtree.c(1560): 240 candidate words for entering last phone (2/fr)
INFO: ngram_search_fwdtree.c(1562): fwdtree 0.02 CPU 0.017 xRT
INFO: ngram_search_fwdtree.c(1565): fwdtree 0.50 wall 0.521 xRT
INFO: ngram_search_fwdtree.c(1549): 998 words recognized (7/fr)
INFO: ngram_search_fwdtree.c(1551): 13964 senones evaluated (96/fr)
INFO: ngram_search_fwdtree.c(1553): 5857 channels searched (40/fr), 710 1st, 3774 last
INFO: ngram_search_fwdtree.c(1557): 1155 words for which last channels evaluated (7/fr)
INFO: ngram_search_fwdtree.c(1560): 456 candidate words for entering last phone (3/fr)
INFO: ngram_search_fwdtree.c(1562): fwdtree 0.03 CPU 0.021 xRT
INFO: ngram_search_fwdtree.c(1565): fwdtree 1.38 wall 0.943 xRT
[INFO] [1601811718.184737]: 前进
INFO: cmn_prior.c(121): cmn_prior_update: from < 54.78 -1.85 -2.46 0.13 -2.15 1.33 -1.31 0.32 -0.25 -0.45 0.14 0.63 -0.55 >
INFO: cmn_prior.c(139): cmn_prior_update: to < 55.24 -2.41 -2.57 0.08 -2.31 1.33 -1.44 0.19 -0.21 -0.47 0.21 0.77 -0.55 >
INFO: ngram_search_fwdtree.c(1549): 938 words recognized (7/fr)
INFO: ngram_search_fwdtree.c(1551): 15196 senones evaluated (109/fr)
INFO: ngram_search_fwdtree.c(1553): 7099 channels searched (50/fr), 680 1st, 5104 last
INFO: ngram_search_fwdtree.c(1557): 1224 words for which last channels evaluated (8/fr)
INFO: ngram_search_fwdtree.c(1560): 582 candidate words for entering last phone (4/fr)
INFO: ngram_search_fwdtree.c(1562): fwdtree 0.03 CPU 0.018 xRT
INFO: ngram_search_fwdtree.c(1565): fwdtree 0.90 wall 0.643 xRT
可以通过rostopic查看语音
rostopic echo /recognizer/output
yys@yys:~/catkin_ws/src/pocketsphinx$ tree . ├── CHANGELOG.rst ├── CMakeLists.txt ├── demo │ ├── mandarin_notone.dic │ ├── robocup.corpus │ ├── robocup.dic │ ├── robocup.launch │ ├── robocup.lm │ ├── robocup_r1.launch │ ├── robocup_r2.launch │ ├── tdt_sc_8k │ │ ├── feat.params │ │ ├── mdef │ │ ├── means │ │ ├── noisedict │ │ ├── sendump │ │ ├── transition_matrices │ │ └── variances │ ├── turtlebot_voice_cmd.launch │ ├── voice_cmd.corpus │ ├── voice_cmd.dic │ ├── voice_cmd.launch │ ├── voice_cmd.lm │ ├── wake.dic │ └── wake.lm ├── nodes │ ├── recognizer.py │ └── voice_cmd_vel.py ├── package.xml └── README.md
对着麦克风说话,输出等级出现波动,说明麦克风有作用
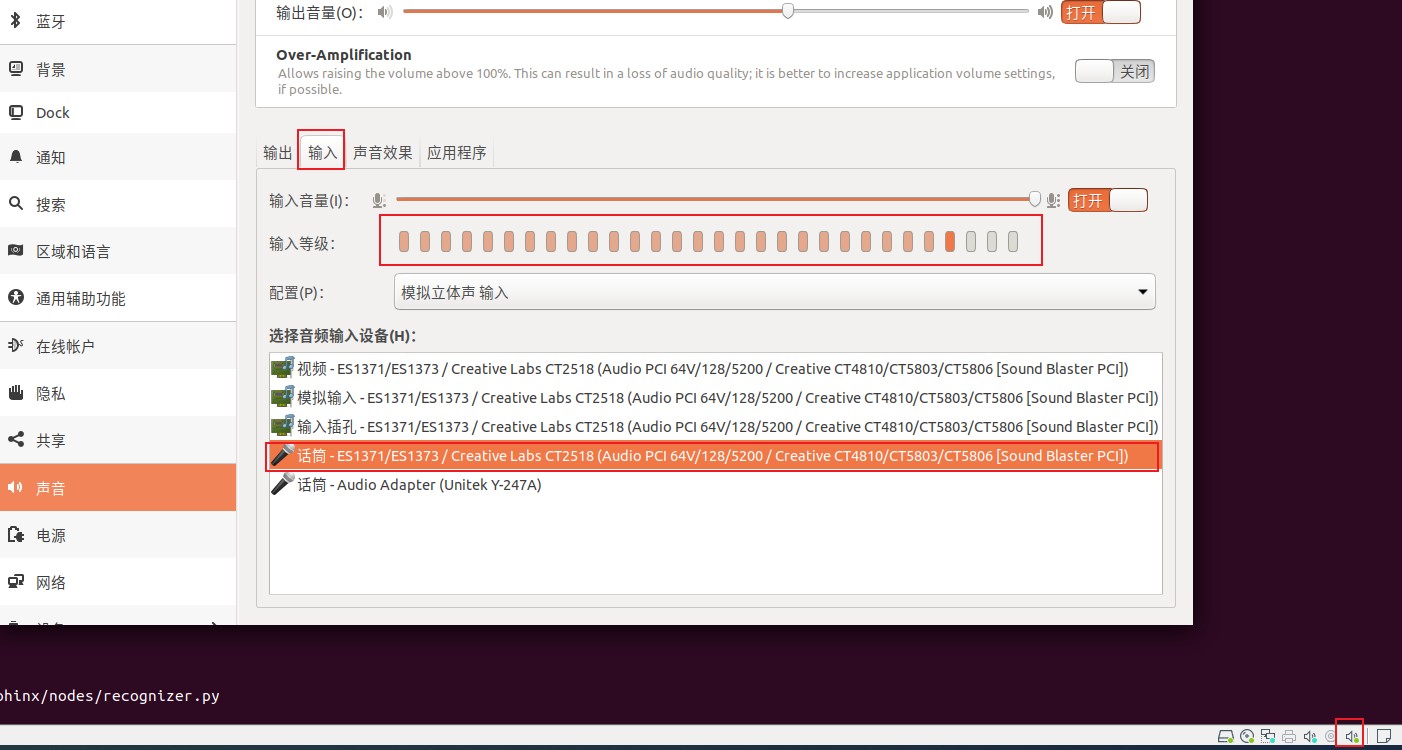
想要安装语音播报软件espeak,这个软件说中文有英文的感觉,不知道怎么变音
sudo apt-get install espeak
vim ~/catkin_ws/src/pocketsphinx/nodes/voice_cmd_vel.py
#!/usr/bin/env python
# -*- coding: utf-8 -*-
import os
import rospy
from geometry_msgs.msg import Twist
from std_msgs.msg import String
import random
import threading
import time
# 初始化ROS节点,声明一个发布速度控制的Publisher
rospy.init_node('voice_teleop')
# pub = rospy.Publisher('/turtle1/cmd_vel', Twist, queue_size=10)
pub = rospy.Publisher('/cmd_vel', Twist, queue_size=100)
r = rospy.Rate(10) # 10
def speak(text):
"""说话线程"""
os.system("espeak -v zh '%s'" % text) # 使用os来文字转语音
def run_obj(twist, s_time=3):
"""控制物体如乌龟,小车线程,s_time多少秒关闭"""
t1 = time.time()
while not rospy.is_shutdown():
# 循环控制
pub.publish(twist)
t2 = time.time()
if t2-t1>s_time:
print("s_time停止")
break
# 接收到语音命令后发布速度指令
def get_voice(data):
voice_text=data.data
rospy.loginfo("I said:: %s",voice_text)
twist = Twist()
print "=====voice_text====%s" % voice_text
text = ""
if voice_text == "前进":
text = random.choice(["我前进拉", "向前冲压"])
twist.linear.y = 5.3
twist.angular.z = -0.5
elif voice_text == "后退" or voice_text == "后" or voice_text == "退":
twist.linear.x = -1.3
text = random.choice(["我后退拉", "请注意!倒车"])
elif voice_text == "left":
twist.angular.z = 0.3
elif voice_text == "right":
twist.angular.z = -0.3
print twist
t1 =threading.Thread(target=speak, args=(text,))
t1.start()
t2 =threading.Thread(target=run_obj, args=(twist,3,))
t2.start()
#os.system("rostopic pub -1 /voice/xf_tts_topic std_msgs/String %s" % text)
# 订阅pocketsphinx语音识别的输出字符
def teleop():
rospy.loginfo("Starting voice Teleop")
rospy.Subscriber("/recognizer/output", String, get_voice)
rospy.spin()
while not rospy.is_shutdown():
teleop()
roslaunch pocketsphinx voice_cmd.launch
rosrun turtlesim turtlesim_node
然后可以说话了(说后退识别不标准)
8.1下载英文语音包pocketsphinx-hmm-en-tidigits (0.8-5):下载
在包pocketsphinx下面建一个model目录,存放语音模型文件
cd ~/catkin_ws/src/pocketsphinx
mkdir model
将下载好的语音文件,解压后,将其中的model文件下的所有文件拷贝到~/catkin_ws/src/pocketsphinx/model下
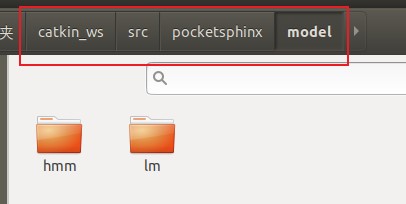
8.2.修改文件
vim ~/catkin_ws/src/pocketsphinx/nodes/recognizer.py
#!/usr/bin/env python
#-*- coding:UTF-8 -*-
"""
recognizer.py is a wrapper for pocketsphinx.
parameters:
~lm - filename of language model
~dict - filename of dictionary
~mic_name - set the pulsesrc device name for the microphone input.
e.g. a Logitech G35 Headset has the following device name: alsa_input.usb-Logitech_Logitech_G35_Headset-00-Headset_1.analog-mono
To list audio device info on your machine, in a terminal type: pacmd list-sources
publications:
~output (std_msgs/String) - text output
services:
~start (std_srvs/Empty) - start speech recognition
~stop (std_srvs/Empty) - stop speech recognition
"""
import roslib; roslib.load_manifest('pocketsphinx')
import rospy
import pygtk
pygtk.require('2.0')
import gtk
import gobject
import pygst
pygst.require('0.10')
gobject.threads_init()
import gst
from std_msgs.msg import String
from std_srvs.srv import *
import os
import commands
class recognizer(object):
""" GStreamer based speech recognizer. """
def __init__(self):
# Start node
rospy.init_node("recognizer")
self._device_name_param = "~mic_name" # Find the name of your microphone by typing pacmd list-sources in the terminal
self._lm_param = "~lm"
self._dic_param = "~dict"
self._hmm_param = "~hmm" #增加hmm参数
# Configure mics with gstreamer launch config
if rospy.has_param(self._device_name_param):
self.device_name = rospy.get_param(self._device_name_param)
self.device_index = self.pulse_index_from_name(self.device_name)
self.launch_config = "pulsesrc device=" + str(self.device_index)
rospy.loginfo("Using: pulsesrc device=%s name=%s", self.device_index, self.device_name)
elif rospy.has_param('~source'):
# common sources: 'alsasrc'
self.launch_config = rospy.get_param('~source')
else:
self.launch_config = 'gconfaudiosrc'
rospy.loginfo("Launch config: %s", self.launch_config)
self.launch_config += " ! audioconvert ! audioresample " \
+ '! vader name=vad auto-threshold=true ' \
+ '! pocketsphinx name=asr ! fakesink'
# Configure ROS settings
self.started = False
rospy.on_shutdown(self.shutdown)
self.pub = rospy.Publisher('~output', String)
rospy.Service("~start", Empty, self.start)
rospy.Service("~stop", Empty, self.stop)
if rospy.has_param(self._lm_param) and rospy.has_param(self._dic_param):
self.start_recognizer()
else:
rospy.logwarn("lm and dic parameters need to be set to start recognizer.")
def start_recognizer(self):
rospy.loginfo("Starting recognizer... ")
self.pipeline = gst.parse_launch(self.launch_config)
self.asr = self.pipeline.get_by_name('asr')
self.asr.connect('partial_result', self.asr_partial_result)
self.asr.connect('result', self.asr_result)
# self.asr.set_property('configured', True)
self.asr.set_property('dsratio', 1)
# Configure language model
if rospy.has_param(self._lm_param):
lm = rospy.get_param(self._lm_param)
else:
rospy.logerr('Recognizer not started. Please specify a language model file.')
return
if rospy.has_param(self._dic_param):
dic = rospy.get_param(self._dic_param)
else:
rospy.logerr('Recognizer not started. Please specify a dictionary.')
return
#读取hmm属性,从配置文件中
if rospy.has_param(self._hmm_param):
hmm = rospy.get_param(self._hmm_param)
else:
rospy.logerr('Recognizer not started. Please specify a hmm.')
return
self.asr.set_property('lm', lm)
self.asr.set_property('dict', dic)
self.asr.set_property('hmm', hmm) #设置hmm属性
self.bus = self.pipeline.get_bus()
self.bus.add_signal_watch()
self.bus_id = self.bus.connect('message::application', self.application_message)
self.pipeline.set_state(gst.STATE_PLAYING)
self.started = True
def pulse_index_from_name(self, name):
output = commands.getstatusoutput("pacmd list-sources | grep -B 1 'name: <" + name + ">' | grep -o -P '(?<=index: )[0-9]*'")
if len(output) == 2:
return output[1]
else:
raise Exception("Error. pulse index doesn't exist for name: " + name)
def stop_recognizer(self):
if self.started:
self.pipeline.set_state(gst.STATE_NULL)
self.pipeline.remove(self.asr)
self.bus.disconnect(self.bus_id)
self.started = False
def shutdown(self):
""" Delete any remaining parameters so they don't affect next launch """
for param in [self._device_name_param, self._lm_param, self._dic_param]:
if rospy.has_param(param):
rospy.delete_param(param)
""" Shutdown the GTK thread. """
gtk.main_quit()
def start(self, req):
self.start_recognizer()
rospy.loginfo("recognizer started")
return EmptyResponse()
def stop(self, req):
self.stop_recognizer()
rospy.loginfo("recognizer stopped")
return EmptyResponse()
def asr_partial_result(self, asr, text, uttid):
""" Forward partial result signals on the bus to the main thread. """
struct = gst.Structure('partial_result')
struct.set_value('hyp', text)
struct.set_value('uttid', uttid)
asr.post_message(gst.message_new_application(asr, struct))
def asr_result(self, asr, text, uttid):
""" Forward result signals on the bus to the main thread. """
struct = gst.Structure('result')
struct.set_value('hyp', text)
struct.set_value('uttid', uttid)
asr.post_message(gst.message_new_application(asr, struct))
def application_message(self, bus, msg):
""" Receive application messages from the bus. """
msgtype = msg.structure.get_name()
if msgtype == 'partial_result':
self.partial_result(msg.structure['hyp'], msg.structure['uttid'])
if msgtype == 'result':
self.final_result(msg.structure['hyp'], msg.structure['uttid'])
def partial_result(self, hyp, uttid):
""" Delete any previous selection, insert text and select it. """
rospy.logdebug("Partial: " + hyp)
def final_result(self, hyp, uttid):
""" Insert the final result. """
msg = String()
msg.data = str(hyp.lower())
rospy.loginfo(msg.data)
self.pub.publish(msg)
if __name__ == "__main__":
start = recognizer()
gtk.main()
vim ~/catkin_ws/src/pocketsphinx/demo/voice_cmd.launch
<launch>
<node name="recognizer" pkg="pocketsphinx" type="recognizer.py" output="screen">
<param name="lm" value="$(find pocketsphinx)/model/lm/en/tidigits.DMP"/>
<param name="dict" value="$(find pocketsphinx)/model/lm/en/tidigits.dic"/>
<param name="hmm" value="$(find pocketsphinx)/model/hmm/en/tidigits"/>
</node>
</launch>
8.3 语音合成
在ROS中已经集成了完整的语音合成包source_play,只支持英文的语音合成,执行如下命令,即可测试
rosrun sound_play soundplay_node.py
rosrun sound_play say.py "hi, i am diego."
10.语音控制雄安车
本文作者: 永生
本文链接: https://yys.zone/detail/?id=138
版权声明: 本博客所有文章除特别声明外,均采用 CC BY-NC-SA 4.0 许可协议。转载请注明出处!
评论列表 (0 条评论)