计算机视觉opencv
每像素24位比特编码的RGB值:
使用三个8位无符号整数(0到255)表示红色、绿色和蓝色的强度。
这是当前主流的标准表示方法,它可以产生一千六百万种颜色组合,对人类的眼睛来说,其中有许多颜色已经是无法确切的分辨。
注意:
在python的opencv包中,三个通道的颜色顺序为:
[蓝色(Blue),绿色(Green),红色(Red)]
一个红色的像素点→[0,0,255]
C:\Users\yys53\OneDrive\python\OPENCV\_01_write_rgb_image.py
import cv2
import numpy as np
# 1.实例化图片到哪列表数据
image_list = [
[[0, 0, 255], [0, 0, 255]],
[[0, 255, 0], [0, 255, 0]],
[[255, 0, 0], [255, 0, 0]],
]
# 2.列表转换化numpy数组中
image_array = np.array(image_list)
# 3.把数组对象写入特定文件中
cv2.imwrite('images/rgb.png', image_array)
cv2.imwrite('images/rgb.jpg', image_array)
# jpg和png图片不一样
|
rgb.png |
rgb.jpg |


C:\Users\yys53\OneDrive\python\OPENCV\_02_show_rgb_image.py
import cv2
# 读取刚才保存的图片,像素内容,形状或维度信息
# 1.读取图片
img = cv2.imread('images/rgb.png')
img2 = cv2.imread('images/rgb.jpg')
# 2.查看像素内容
print(img)
print(img2)
# 3.查看形状或维度信息
print(img.shape)
print(img2.shape)
# (3, 2, 3)表达(三根线,每根线两个像素点组成,每个像素点三通道组成)
gray_img.shape为(3,2, 3)
C:\Users\yys53\OneDrive\python\OPENCV\_03_rgb_to_gray.py
import cv2
# 把图片转成灰色,查看图片信息和维度,保存
# 1.读取图片
img = cv2.imread('images/phone.png')
# 2.把图片转成灰色
gray_img = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
# 3.查看像素内容
print(gray_img)
# 4.查看图片维度
print(gray_img.shape)
# 5.保存灰色图片
cv2.imwrite('images/gray_phone.png', gray_img)
gray_img.shape为(523, 1039)比第二个案例少一维
 phone.png phone.png |
 gray_phone.png gray_phone.png |
计算机中的灰度图像是用二维数组表示的,灰度图像起到了降维的作用,方便计算机快速处理
由于python3.7 32位不兼容dlib,所以用linux上
VMware打开摄像头
①linux开机情况下乌班图小按钮打开连接
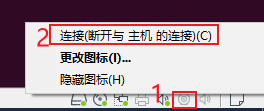
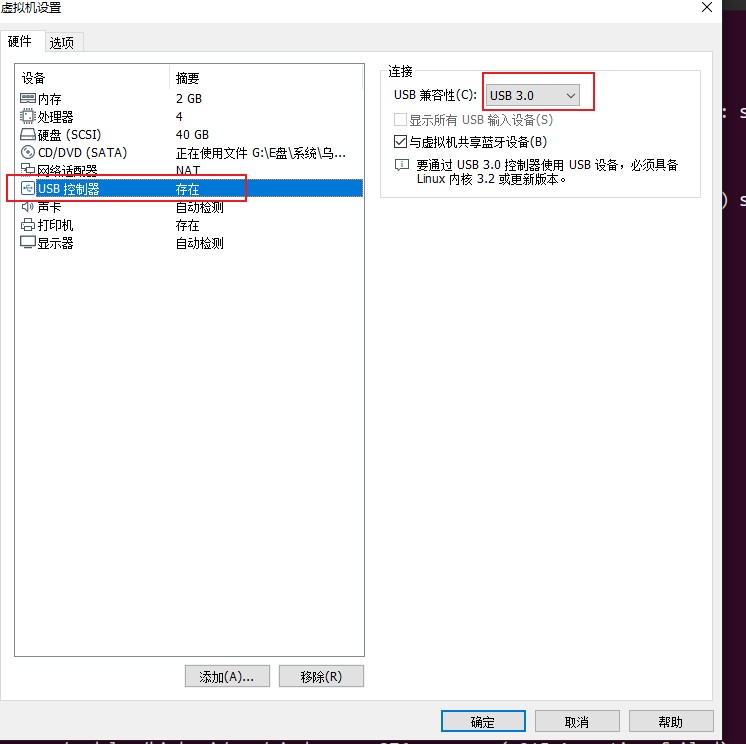
②linux开机情况下设置→usb控制器→选usb3.0
import face_recognition
import cv2
# 打开摄像头,读取摄像头拍摄到的画面,
# 定位到画面中人的脸部,并用绿色的框框把人的脸部框住
# 1. 打开摄像头, 获取摄像头对象
video_capture = cv2.VideoCapture(0) # 0代表的是第一个摄像头
# 2. 循环不停的去获取摄像头拍摄到的画面,并做进一步的处理
while True:
# TODO 还需要做进一步的处理
# 2.1 获取摄像头拍摄到的画面
ret, frame = video_capture.read() # frame 摄像头所拍摄的画面
# 2.2 从拍摄到的画面中提取出人的脸部所在区域(可能会有多个)
face_locations = face_recognition.face_locations(frame)
# 2.3 循环遍历人的脸部所在区域,并画框
for top, right, bottom, left in face_locations:
# 2.3.1 在人像所在区域画框
# BGR
cv2.rectangle(frame, (left, top), (right, bottom), (0, 255, 0),2)
# 2.4 通过opencv把拍摄到的并画了框的画面展示出来
cv2.imshow("Video", frame)
# 2.5 设定按q退出While循环,退出程序的这样一个机制
if cv2.waitKey(1) & 0xFF == ord('q'):
break # 退出while循环
# 3. 退出程序的时候,释放摄像头或其他资源
video_capture.release()
cv2.destroyAllWindows()
import cv2
import face_recognition
import os
# 一:打开摄像头,读取摄像头拍摄到的画面,
# 定位到画面中人的脸部,并用绿色的框框把人的脸部框住
# 二:读取到数据库中的人名和面部特征
# 三:用拍摄到人的脸部特征和数据库中的面部特征去匹配,
# 并在用户头像的绿框上方用用户的姓名做标识,未知用户统一使用Unkown
# 四: 定位和锁定目标人物,改使用红色的框框把目标人物的脸部框住
my = ["yys", 'yys1']
# 读取数据库人脸和面部特征
#1.准备工作
face_databases_path = 'face_databases'
user_names = [] # 存储用户名
user_face_encodings = [] # 存储用户面部特征向量
# 2.正式工作
# 2.1 得到face——databases——path文件夹所有用户名
face = os.listdir(face_databases_path)
# 2.2for循环读取文件名进一步处理
for image_short_name in face:
# 2.2.1 截取文件名前面那部分作为用户名存入user——names的列表中
user_name,_ = os.path.splitext(image_short_name)
user_names.append(user_name)
# 2.2.2 读取图片文件中的面部特征信息存入user_faces_encodings中
image_file_name = os.path.join(face_databases_path,image_short_name)
image_file = face_recognition.load_image_file(image_file_name)
pic_face_encoding = face_recognition.face_encodings(image_file)[0]
user_face_encodings.append(pic_face_encoding)
# 打开摄像头,读取摄像头拍摄到的画面,
# 定位到画面中人的脸部,并用绿色的框框把人的脸部框住
# 1. 打开摄像头, 获取摄像头对象
video_capture = cv2.VideoCapture(0) # 0代表的是第一个摄像头
# 2. 循环不停的去获取摄像头拍摄到的画面,并做进一步的处理
while True:
# 2.1 获取摄像头拍摄到的画面
ret, frame = video_capture.read() # frame 摄像头所拍摄的画面
# 2.2 从拍摄到的画面中提取出人的脸部所在区域(可能会有多个)
# ['第一个人脸所在区域', '第二个人脸所在区域' ...]
face_locations = face_recognition.face_locations(frame)
# 2.21 从所有人的头像所在区域提取出脸部特征(可能会有多个)
# ['第一个人脸对应的面部特征', '第二个人脸对应的面部特征' ...]
face_encodings = face_recognition.face_encodings(frame, face_locations)
# 2.21 从所有人的头像所在区域提取出脸部特征(可能会有多个)
# ['第一个人的姓名', '第二个人的姓名' ...]
# 如果特征匹配不上数据库中的特征,则是Unknown
names = []
# 遍历face_encodings,和之前数据库中面部特征做匹配
for face_encoding in face_encodings:
# compare_faces(['面部特征1', '面部特征2', '面部特征3' ... ], 未知的面部特征)
# compare_faces返回结果
# 假如 未知的面部特征 和 面部特征1 匹配, 和 面部特征2 面部特征3 不匹配
# [True, False, False]
# 假如 未知的面部特征 和 面部特征2 匹配, 和 面部特征1 面部特征3 不匹配
# [False, True, False ]
matchs = face_recognition.compare_faces(user_face_encodings, face_encoding)
# user_names
# ['第一个人的姓名','第二个人的姓名', '第三个人的姓名' ...]
name = "unknow"
for index, is_match in enumerate(matchs):
# [False, True, False ]
# 0 , False
# 1 , True
# 2, False
if is_match:
name = user_names[index]
break
names.append(name)
# 2.3 循环遍历人的脸部所在区域,并画框
# zip
# zip(['第1个人的位置', '第2个人的位置'], ['第1个人的姓名', '第2个人的姓名'])
# for
# '第1个人的位置', '第1个人的姓名'
# '第2个人的位置', '第2个人的姓名'
for (top, right, bottom, left), name in zip(face_locations, names):
# 2.3.1 在人像所在区域画框
# BGR
color = (0, 255, 0)
if name in my:
color = (0, 0, 255)
cv2.rectangle(frame, (left, top), (right, bottom), color,2)
font = cv2.FONT_HERSHEY_DUPLEX
# 在框上写名字,各参数依次是:图片,添加的文字,左上角坐标,字体,字体大小,颜色,字体粗细
cv2.putText(frame, name, (left, top-10),font, 0.5 ,color,1)
# 2.4 通过opencv把拍摄到的并画了框的画面展示出来
cv2.imshow("Video", frame)
# 2.5 设定按q退出While循环,退出程序的这样一个机制
if cv2.waitKey(1) & 0xFF == ord('q'):
break # 退出while循环
# 3. 退出程序的时候,释放摄像头或其他资源
video_capture.release()
cv2.destroyAllWindows()
微信公众平台开发运动传感器
差分法原理(类似连连看找不同)
|
图1 [ |
图2 [ |
| |图1-图2|= |
[ [ 10,50], [ 0,0], [ 10,0], ] |
运动传感器的实现
基于微信公众平台的开发
代码封装和优化的过程:
面相过程->面相函数->面相对象
②获取消息接口
消息管理→客服消息→2 客服接口-发消息
发送文本消息
https请求方式: GET https://api.weixin.qq.com/cgi-bin/token?grant_type=client_credential&appid=APPID&secret=APPSECRET
{
"touser":"OPENID",
"msgtype":"text",
"text":
{
"content":"Hello World"
}
}
③获取access_token
开始开发→获取Access token
接口调用说明
http请求方式: POST https://api.weixin.qq.com/cgi-bin/message/custom/send?access_token=ACCESS_TOKEN
import json
import requests
class WxTools:
def __init__(self, app_id, app_secret):
self.app_id = app_id
self.app_secret = app_secret
def get_access_token(self):
# 1.获取access_token
# https请求方式get
url = 'https://api.weixin.qq.com/cgi-bin/token?grant_type=client_credential&appid={}&secret={}'.format(
self.app_id, self.app_secret)
resp = requests.get(url).json()
access_token = resp.get('access_token')
return access_token
def send_wx_message(self, open_id, msg='有人闯入你的家'):
# 2.利用token_secret发送微信通知
url = 'https://api.weixin.qq.com/cgi-bin/message/custom/send?access_token={}'.format(self.get_access_token())
req_data = {
"touser": open_id,
"msgtype": "text",
"text":
{
"content": msg
}
}
req_str = json.dumps(req_data, ensure_ascii=False)
req_data = req_str.encode('utf-8')
requests.post(url, data=req_data)
if __name__ == '__main__':
app_id = 'wxefb72b125a8cf483' # 接收消息用户的id
app_secret = '53c222dfe9e946abe171f1742c1e0623'
access_token = WxTools(app_id, app_secret)
open_id = 'oBlvz589opZjjuLgFBkQX6j-VN3A'
msg = '有人闯入你的家'
access_token.send_wx_message(open_id, msg)
import cv2
import datetime
from _05_wx_notice3 import WxTools
app_id = 'wxefb72b125a8cf483' # 接收消息用户的id
app_secret= '53c222dfe9e946abe171f1742c1e0623'
open_id = 'oBlvz589opZjjuLgFBkQX6j-VN3A'
msg = '有人闯入你的家'
camera = cv2.VideoCapture(0)
background = None # 存储第一张图片
es = cv2.getStructuringElement(cv2.MORPH_ELLIPSE, (5, 4)) # 形态学膨胀
is_send_msg = False # 标识有没有发送过通知,只发送一次,防止骚扰
while True:
grabbed, frame = camera.read()
gray_frame = cv2.cvtColor(frame, cv2.COLOR_BGR2GRAY) # 转灰度图像,提高速度
gray_frame = cv2.GaussianBlur(gray_frame, (25, 25), 3) # 高斯滤波,消除噪点
if background is None:
background = gray_frame
continue
# 差分法求背景图和灰度图的差
diff = cv2.absdiff(background, gray_frame)
# 超过50就算不一样,小于50就算一样,小于50就算0,大于50就算255
diff = cv2.threshold(diff, 50, 255, cv2.THRESH_BINARY)[1]
# 形态学膨胀优化差值
diff = cv2.dilate(diff, es, iterations=3)
# 参数1:为了防止后面展示修改diff所以copy一份,参数2:外部轮廓。参数3:判断连续
contours, hierarchy = cv2.findContours(diff.copy(), cv2.RETR_EXTERNAL,
cv2.CHAIN_APPROX_SIMPLE)
is_detected = False
for c in contours:
if cv2.contourArea(c) < 2000: # 如果连续不同物体小于2000,跳过
continue
(x, y, w, h) = cv2.boundingRect(c) # 如果大于2000,就在原图像上画框
cv2.rectangle(frame, (x, y), (x + w, y + h), (0, 255, 0), 2)
is_detected = True
if not is_send_msg:
is_send_msg = True
wx_tools = WxTools(app_id, app_secret)
wx_tools.send_wx_message(open_id, msg)
if is_detected: # 探测到就改成红色
show_text = "Motion: Detected"
show_color = (0, 0, 255)
else: # 没有探测到绿色
show_text = "Motion: Undetected"
show_color = (0, 255, 0)
# 上面文字
cv2.putText(frame, show_text, (10, 20),
cv2.FONT_HERSHEY_SIMPLEX, 0.5, show_color, 2)
# 下面的字,时间
cv2.putText(frame, datetime.datetime.now().strftime("%b %d %Y %H:%M:%S"), (10, frame.shape[0] - 10), cv2.FONT_HERSHEY_SIMPLEX, 0.35, show_color, 1)
# 窗口名字
cv2.imshow('video', frame)
cv2.imshow('diff', diff)
key = cv2.waitKey(1) & 0xFFf
if key == ord('q'):
break
camera.release()
cv2.destroyAllWindows()
本文作者: 永生
本文链接: https://yys.zone/detail/?id=119
版权声明: 本博客所有文章除特别声明外,均采用 CC BY-NC-SA 4.0 许可协议。转载请注明出处!
评论列表 (0 条评论)